
유니티의 ML-Agents 2.0 TUTORIAL 영상을 대략적인 정리한 글입니다.
Version : Unity 2021.3.5f1
에피소드의 시작과 끝
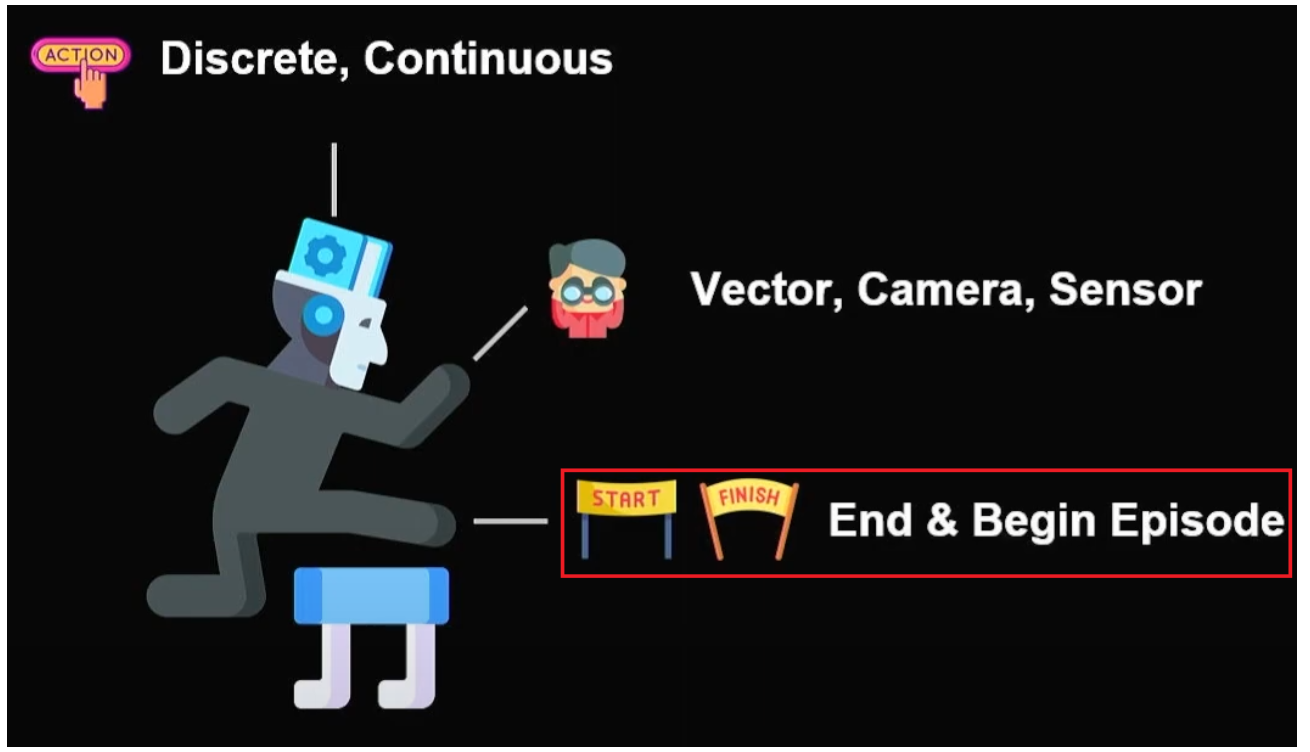
(End&Start) 시작과 종료 조건을 사용할 때 고민해봐야할 것
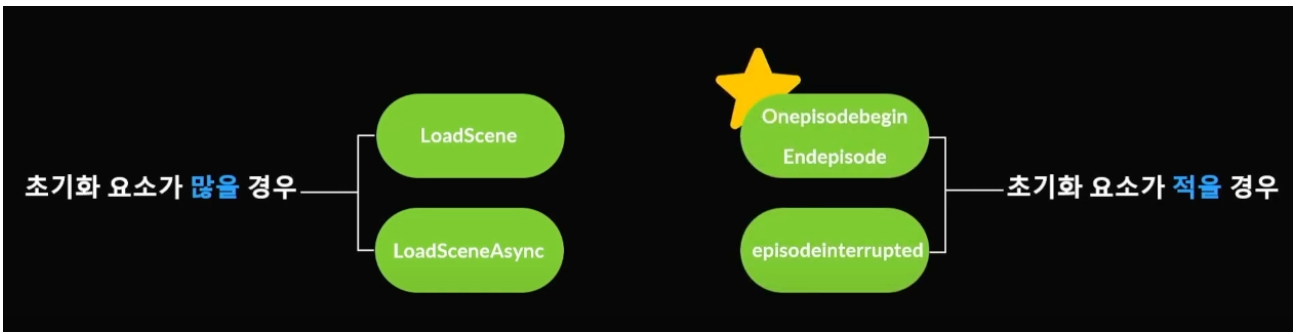
초기화 요소가 많을 경우 학습 속도의 저하 / 학습 노이즈를 제공할 수 있다.

EndEpisode // OnEpisodeBegin
초기화 요소가 적을경우
3D Ball 예제를 살펴보자


Hallway 예제

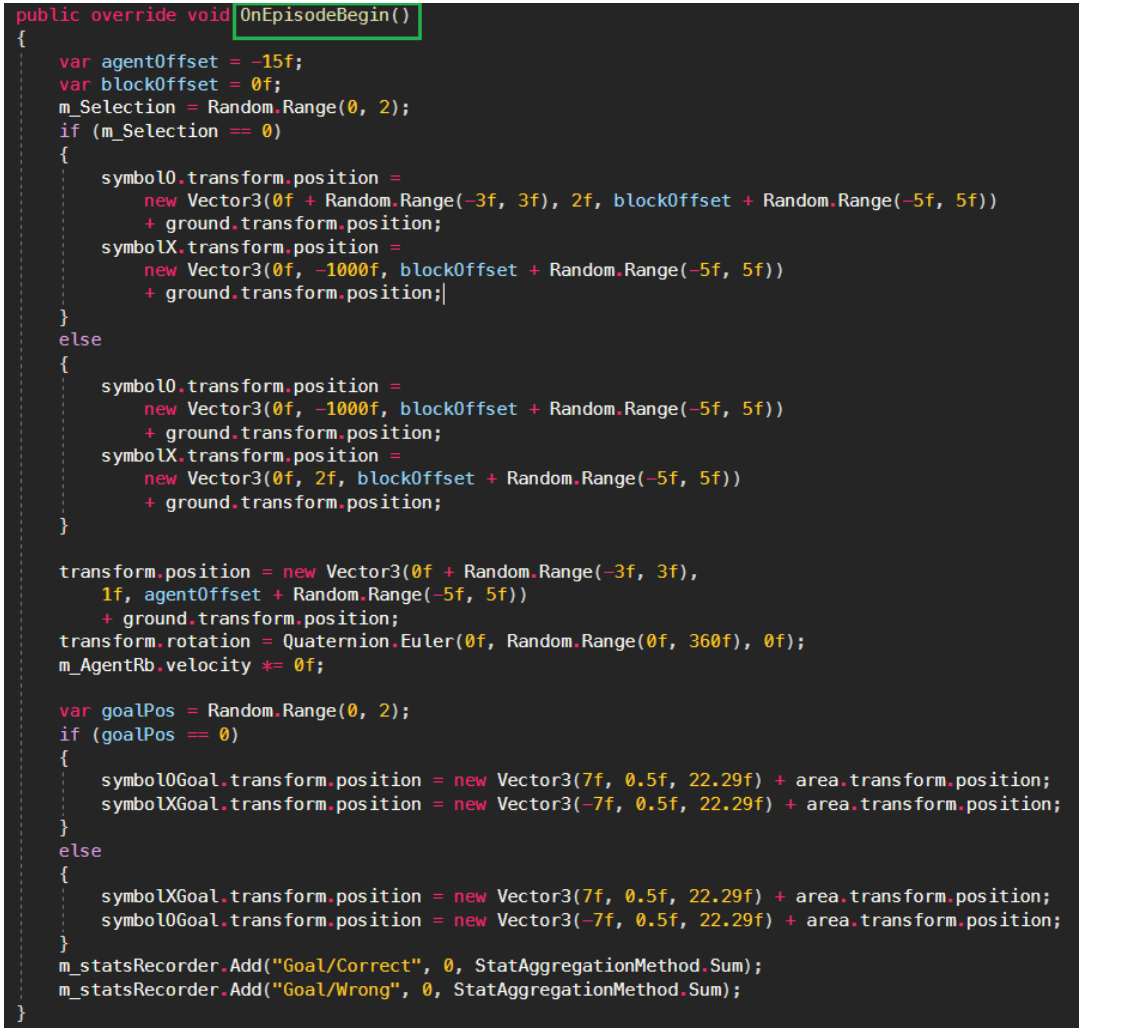
Initialize() ==> EndEpisode() => OnEpisodeBegin() ==> EndEpisode() => OnEpisodeBegin() ……..
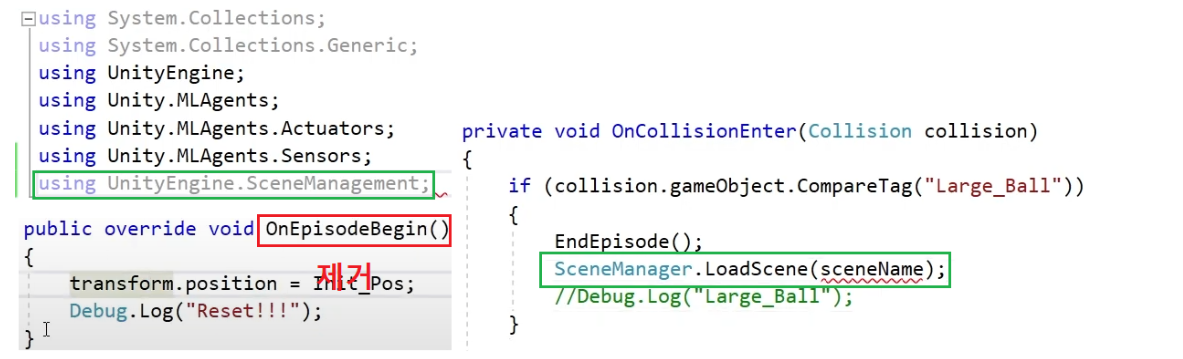
초기화 요소가 많을경우
OnEpisodeBegin() 을 제거하고 EndEpisode() 다음에 씬전환을 해준다.
보상
에이전트가 보상을 받을 수 있도록 해줘야한다.

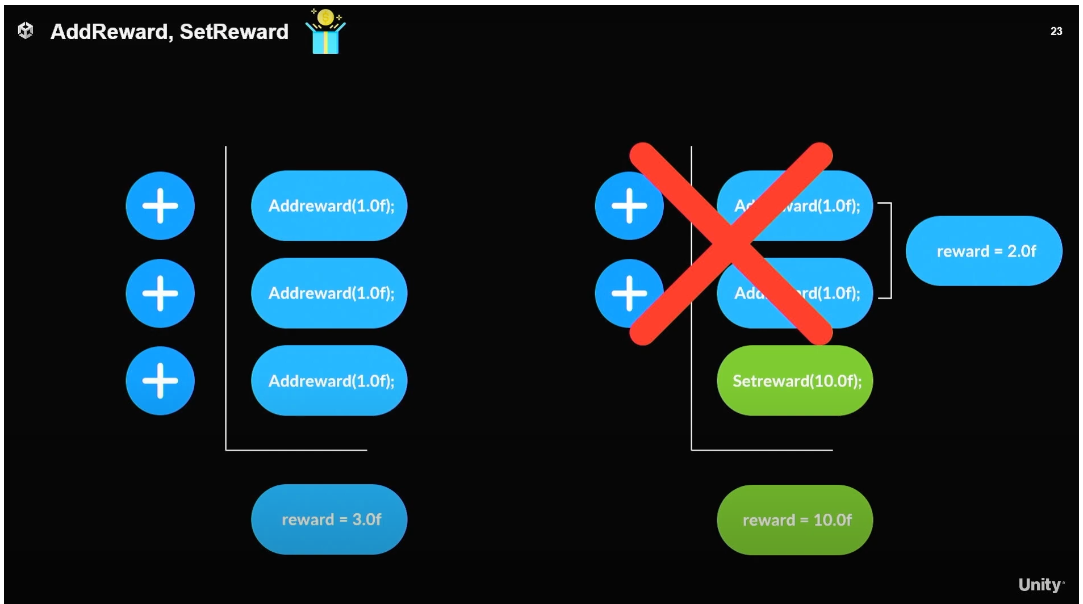
Addreward 와 Setreward 를 잘 사용하자

예를 들어 에이전트가 목표와의 거리가 가까워졌는지 판단하고 이를 통해 보상을 주는 방법
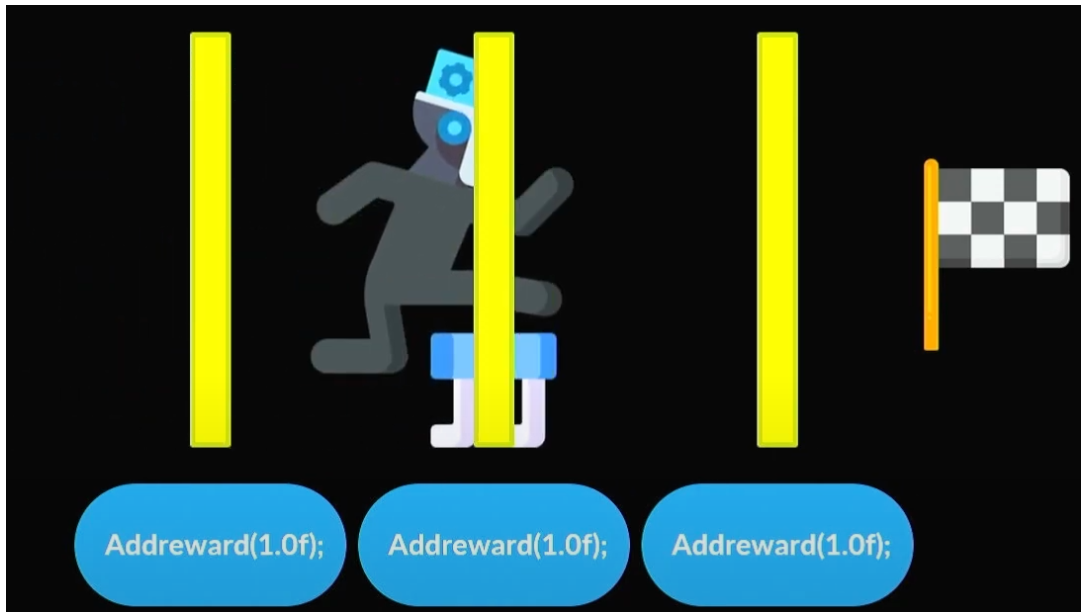
특정구간 (체크포인트) 를 지날 때마다 점수를 주는방법

3D ball 과 환경과 같이 행동을 할때마다 보상을 주는 방법

에이전트가 행동을 할때마다 점수를 감점시키는 방법 등 다양한 방법이 있다.
알고리즘 하이퍼 파라미터 튜닝
참고자료들
https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-ML-Agents.md
https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md

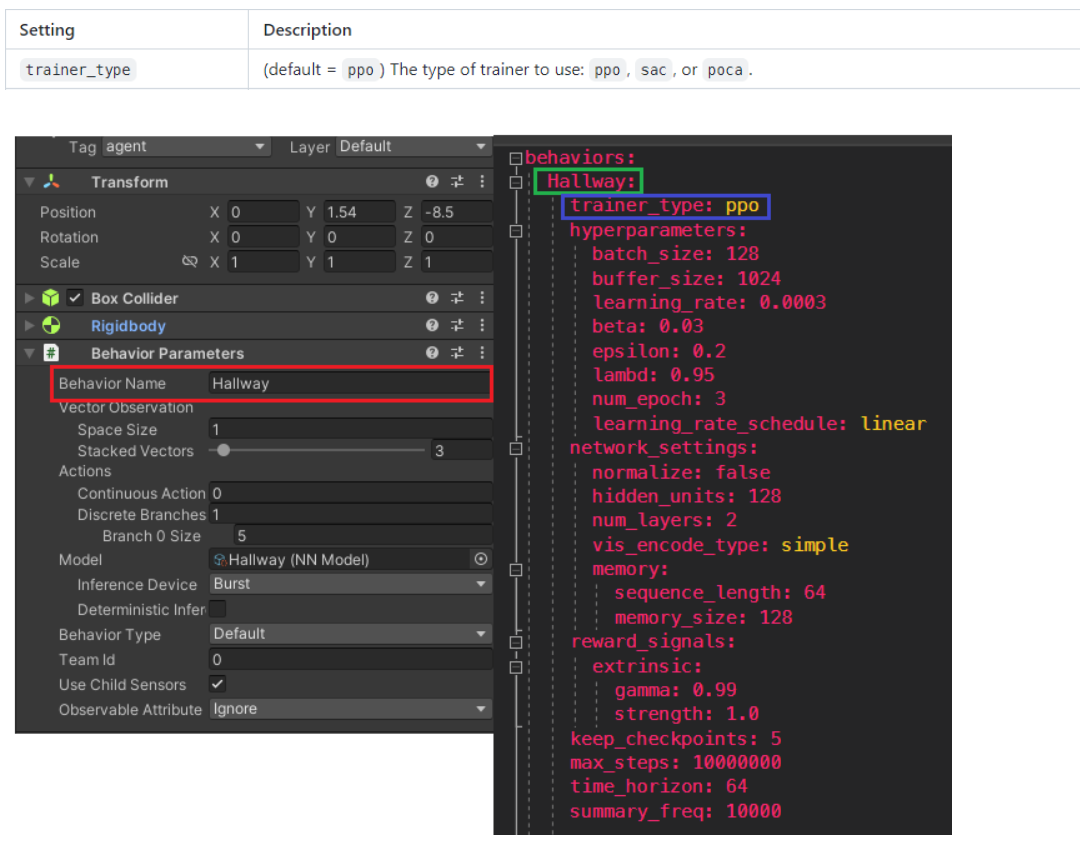
예제의 Hallway 의 하이퍼 파라미터
behaviors:
Hallway:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 1024
learning_rate: 0.0003
beta: 0.03
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory:
sequence_length: 64
memory_size: 128
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 64
summary_freq: 10000
behavior Name 을 동일하게 설정해야한다.
traniner_type
: 학습에 필요한 내장 알고리즘을 결정한다. (기본값 : ppo) / ppo, sac, poca
batch_size
네트워크를 한번 학습할 때 몇개의 데이터를 사용할지 결정한다.
– 일반적인 설정 – 2의 배수로 설정을 추천
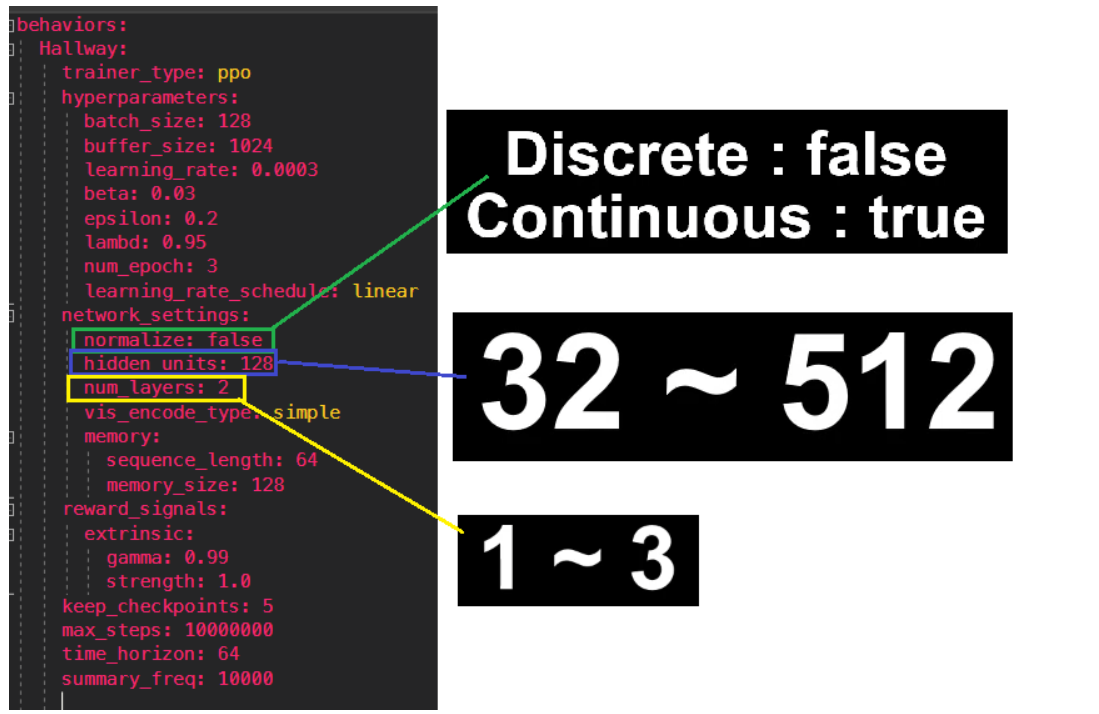
continuous action (128~5120)
Discrete action (32~512)

buffer_size
: 정책을 업데이트 하기 전에 수집하는 경험의 데이터의 수
사이즈가 클수록 안정적인 학습이 가능합니다.
– 일반적인 설정 –
2의 배수로 설정을 추천 + batch_size 의 배수로 설정
2048 ~ 409600
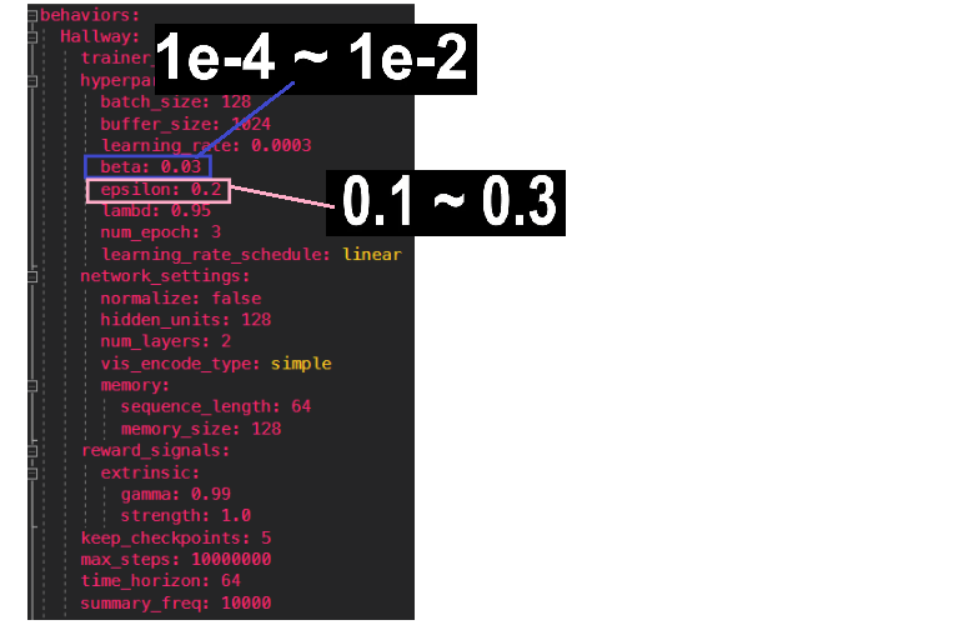
learning_rate
: 경사 하강법의 대한 초기학습률
기본값 = 3e-4 ( 학습을 위한 초기 학습값 )
훈련이 불안정하거나 보상이 지속적으로 증가하지 않을 때 값을 줄인다.

beta
: 정책을 더 무작위로 만드는 엔트로피 값입니다.
이 값이 높을수록 더 랜덤 행동을 많이 하게 됩니다. ( 많은 탐험 수행 )
텐서보드에서 아직 학습이 잘되지 않았음에도 불구하고 엔트로피의 값이 너무 빠르게 떨어질경우 이 값을 높여야 합니다.
기본값 = 5e-3 ( 학습을 위한 초기 학습값 )
cf > Discrete 환경에서는 엔트로피는 0 이하가 될 수 없지만 계산법의 차이로
Continuous 환경에서는 엔트로피가 0 보다 작아질 수도 있다.
본인의 상황에 따라서 텐서 보드를 잘봐야한다.
epsilon
: 정책이 얼마나 빠르게 발전할지 결정합니다. 값을 줄일 수록 더 안정적이지만 학습의 속도가 느리다.
기본값 = 0.2 ( 학습을 위한 초기 학습값, 추천 )
https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md <- 참고 링크

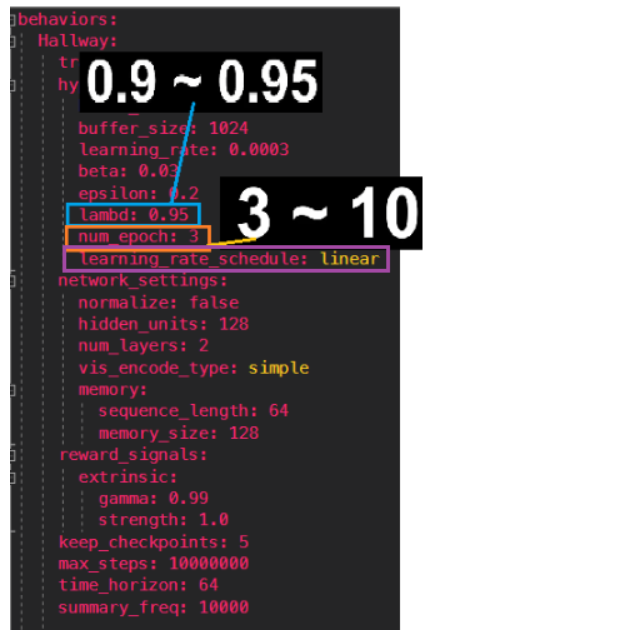
lambd
: 가치 추정에 의존을 할지 아니면 실제 수렴하는 보상에 의존을 할 지 결정하는 값
값이 작을 떄는 가치 추정에 의존을 하고 값이 높으면 실제 수령하는 보상에 의존한다.
– 일반적인 설정 –
0.9 ~0.95
(미래의 보상을 평가할 때 이전까지의 보상을 기준으로 하는 정도).
람다값이 적을수록 지금까지의 보상을 기준으로 미래의 보상을 평가하게 됨.
지금까지의 경향을 유지하는 방향으로 굳어짐.
num_epoch
경험버퍼에 쌓인 데이터에 대하여 학습을 몇번 수행할지 결정합니다.
batch_size 가 커질수록 이 값도 커져야 합니다.
이 값이 작아지면 안정적으로 학습이 가능하지만 학습속도 는 느려진다.
기본값 = 3 ( 학습을 위한 초기 학습값 )
learning_rate 와 같이 학습의 안정성에 대한 파라미터
learning_rate_schedule
: linear(PPO) / constant(SAC) 선택가능
linear – MaxStep에 따라 러닝메이트가 감소하면서 학습이 진행됩니다. ( beta 값이 하락 )
constant – beta 값이 유지됩니다.
에피소드의 길이가 긴 환경에 따라 점차 안정적인 학습을 요구하게 되어 베타값이 하락하면서 더 안정적인 학습을 진행
시간이 변함에 따라 learning rate를 어떻게 변경할지 결정한다.
/ PPO의 경우 max step까지 학습률을 감소시키는 경우 더 안정적으로 학습이 수렴된다.
/ SAC의 경우 전체 학습과정 동안 학습률을 유지하여 자연스럽게 큐 함수값이 수렴할 떄 까지 학습
normalize
: 벡터 관측 입력을 정규화 할지 결정하는 값으로
단순하거나 Discrete 환경에서는 false
복잡하거나 Continuous 환경에서는 true 사용합니다. (공식적으로) <환경이 단순하면 그냥 false하자 >
(입력되는 벡터 관측값들이 정규화가 되어있는지 물어 보는 것.)
우리가 정규화 시킨 상태에서 true로 설정하면 학습성능이 향상된다.
hidden_units
: 인공신경망에 몇개의 유닛을 사용할지 결정을 합니다.
단순한 환경일 경우 작게 그리고 복잡한 환경일수록 크게 설정
num_layers
: 앞서 설정한 hidden_units 의 개수를 결정합니다.
– 일반적인 설정 –
2
vis_encode_type
: 시각적 관찰을 인코딩하는 인코더 유형
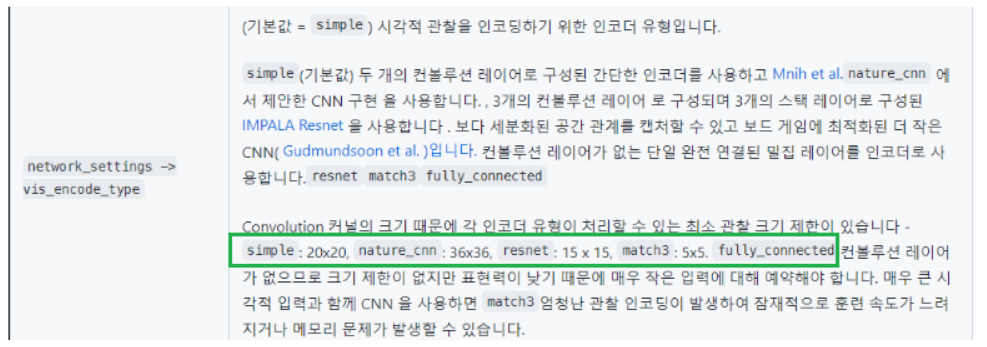
기본적으로 simple 20 x 20 을 사용하지만 값을 더 작거나 크게 만들 수 있다.
reward_signals:
extrinsic:
gamma:
strength:
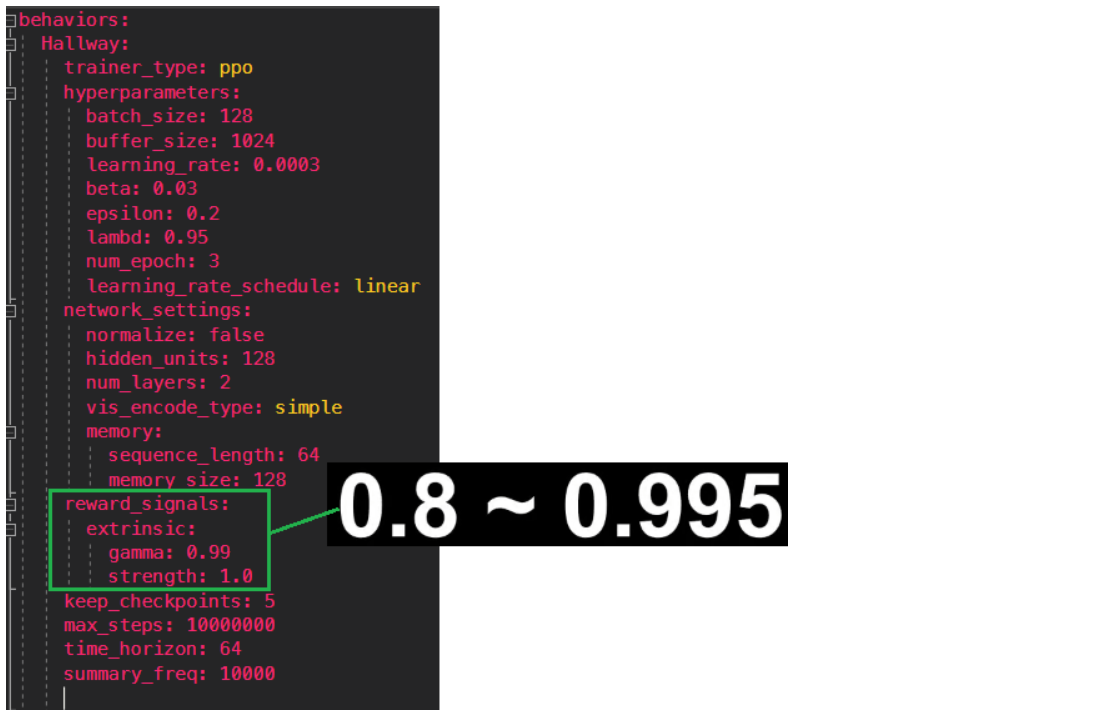
gamma
: 보상 신호의 감마는 할인율과 관련한 값입니다.
절대 1이 넘지 않아야 하고 값이 클수록 원시안적으로 값이 클수록 근시안적으로 에이전트가 행동합니다.
값이 너무 클경우 유도하지 않는 행동을 함에도 불구하고 원시안적으로 행동함으로써 학습에 문제가 생긴다.
(미래의 보상을 현재 평가할 때 적용하는 할인률).
감마값이 적을수록 먼 미래의 보상을 현재에서는 낮게 평가하기 때문에 즉각적인 보상이 상대적으로 높게 평가 됨.
strength
: 설정한 보상에 곱할 인수 일반적으로 1 로 설정
keep_checkpoints
: 몇번 학습모델을 저장할지 설정
10,000,000 / 5 = 2,000,000 스탭마다 저장

max_steps
: 이 예제에서 맥스 스탭은 학습이 진행될 최대의 스텝입니다. (복잡할수록 높아야한다.)
이 값에 도달하게되면 학습이 종료됩니다.
이 값에 따라서 learning rate 가 linear 일 경우 beta 값이 감소

time_horizon
: 경험 버퍼에 저장하기 전에 에이전트가 수집할 경험의 개수입니다.
에피소드가 끝나지 않고 2스텝에 도달하게 되면 에이전트는 점점 보상을 예측합니다.
이 값이 클수록 분산이 커지고 작을수록 분산이 작아집니다.
보상이 잦은 경우에는 작게 설정하는 것이 이상적입니다.

summary_freq
콘솔에 출력되는 학습의 주기입니다.
가독성을 키우기 위해 복잡하고 Maxstep이 높은 환경에서는 크게 단순한 환경에서는 작게 설정합니다.
(학습에 관한 파라미터는 아님)


