
트라이(Trie)?
Trie data structure는 문자열을 효율적으로 저장하고 검색하는 데 사용되는 Tree와 유사한 데이터 구조입니다.
“Trie”라는 이름은 “트리”와 비슷하게 발음되는 “retrieval,”이라는 단어에서 유래되었습니다.
검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어있는 자료구조입니다.
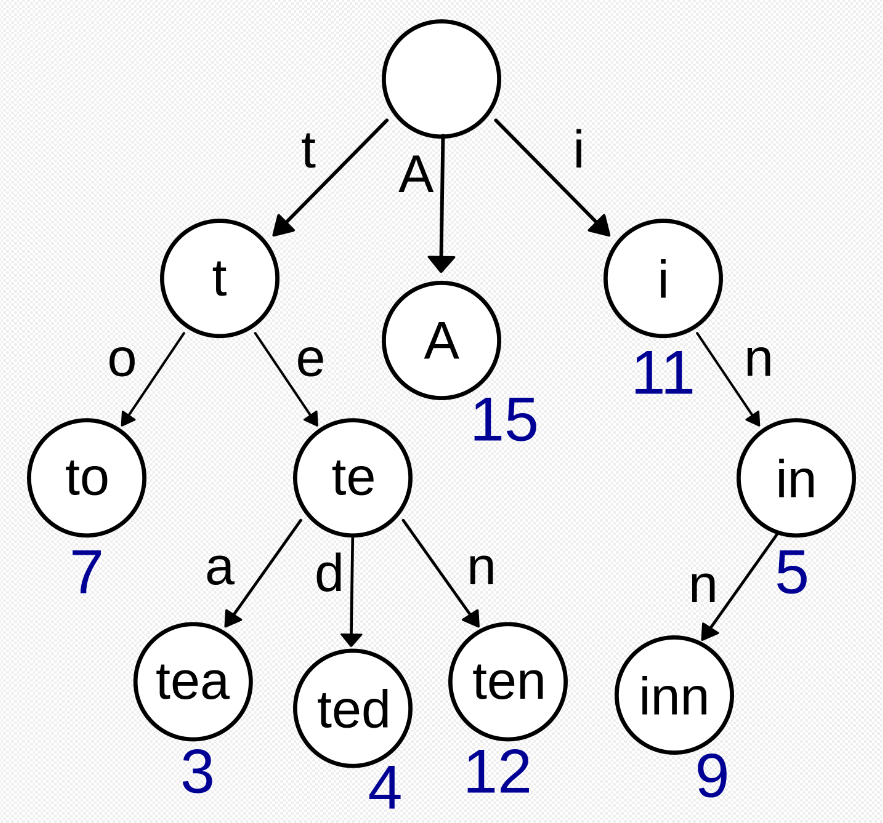
“A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”를 키로 둔 트라이.
이 예제에는 모든 자식 노드가 알파벳 순으로 왼쪽에서 오른쪽으로 정렬되어 있지는 않다. (루트 노드와 ‘t’ 노드)
Trie에서 각 node는 문자열의 단일 문자를 나타내고 node에서 나오는 가장자리는 문자열의 다음 문자를 나타냅니다.
Trie의 각 문자열은 root node에서 leaf node까지의 경로로 표시됩니다.
root node에는 연결된 문자가 없으며 각 leaf node는 데이터 세트의 전체 문자열을 나타냅니다.
Trie는 특히 공통 접두사를 공유하는 문자열을 검색할 때 문자열을 효율적으로 저장하고 검색하는 데 자주 사용됩니다.
예를 들어 Trie를 사용하여 단어 사전을 저장할 수 있습니다.
여기서 Trie의 각 node는 단어의 접두사를 나타냅니다.
Trie를 root node에서 leaf node로 이동하면 leaf node와 관련된 전체 단어를 빠르게 검색할 수 있습니다.
트라이(Trie)의 이점
1. 효율적인 접두사 검색
Trie는 특히 접두사 검색 쿼리에 효율적입니다.
root node에서 접두사를 나타내는 node로 Trie를 순회하면 해당 접두사로 시작하는 데이터 세트의 모든 문자열을 검색할 수 있습니다.
이는 자동 완성, 맞춤법 검사기 및 검색 엔진과 같은 응용 프로그램에서 유용합니다.
2. 공간 효율성
Trie는 해시 테이블과 같은 다른 데이터 구조에 비해 매우 공간 효율적일 수 있습니다.
문자열에 공통 접두사의 중복 저장을 방지하여 특히 문자열 수가 많은 데이터 세트의 경우 공간을 크게 절약할 수 있습니다.
3. 빠른 삽입 및 삭제
Trie는 문자열의 빠른 삽입 및 삭제를 지원하며 최악의 경우 O(m)의 시간 복잡도(m 문자열의 길이)입니다.
따라서 데이터 세트가 동적이며 자주 업데이트해야 하는 애플리케이션에서 유용합니다.
4. 예측 텍스트 입력
Trie는 자동 완성 시스템을 구현하는 데 사용할 수 있습니다.
여기서 시스템은 사용자 입력을 기반으로 다음 단어나 구문을 제안합니다.
자주 사용되는 단어와 구문의 Trie를 저장함으로써
시스템은 사용자의 현재 입력을 기반으로 가장 가능성이 높은 다음 단어를 제안할 수 있습니다.
5. 낮은 메모리 오버헤드
Trie는 특히 ASCII 또는 유니코드와 같은 작은 문자 세트의 경우 메모리 오버헤드가 낮습니다.
따라서 임베디드 시스템 및 기타 메모리 제약 환경에서 사용하기에 적합합니다.
전반적으로 Trie 데이터 구조는 문자열의 데이터 세트를 효율적으로 저장하고 처리하기 위한 강력한 도구입니다.
특히 기본 사용 사례가 접두사를 검색하거나 시퀀스의 다음 단어를 예측하는 경우에 그렇습니다.
트라이(Trie)의 잠재적인 단점
1. 메모리 요구 사항
Trie는 특히 문자열이 길거나 문자 집합이 큰 경우
큰 문자열 데이터 세트를 저장하기 위해 상당한 양의 메모리를 요구할 수 있습니다.
이는 메모리 사용량이 중요한 환경이나 응용 프로그램에서의 사용을 제한할 수 있습니다.
2. 접두사가 아닌 쿼리에 대한 느린 검색 시간
Trie는 접두사 검색 쿼리에 효율적이지만 접두사가 아닌 쿼리에 대한 다른 데이터 구조보다 느릴 수 있습니다.
알고리즘이 쿼리와 일치하는 모든 문자열을 찾기 위해 각 노드의 전체 하위 트리를 탐색해야 하므로
해시 테이블과 같은 다른 데이터 구조에 비해 검색 시간이 느려질 수 있기 때문입니다.
3. 복잡성
Trie 데이터 구조의 구현 및 유지 관리는
엄청나게 큰 데이터 세트의 경우 또는 문자 집합이 매우 복잡한 경우에
다른 데이터 구조보다 더 복잡할 수 있습니다.
이로 인해 개발 시간이 길어지고 개발 비용이 높아질 수 있습니다.
4. 희소 데이터 집합에 대한 비효율적인 메모리 사용
데이터 집합에 희소 문자열이 많이 포함되어 있거나 공통 접두사가 거의 없는 경우
Trie는 가장 메모리 효율적인 데이터 구조가 아닐 수 있습니다.
이는 Trie가 많은 빈 노드를 저장해야 하므로 메모리가 낭비될 수 있기 때문입니다.
전반적으로 Trie 데이터 구조는 효율적인 문자열 처리를 위한 강력한 도구이지만
응용 프로그램의 특정 요구 사항에 따라 항상 최선의 선택이 아닐 수도 있습니다.
트라이(Trie)의 시간 복잡도
일반적으로 Trie의 생성 시간 복잡도는 O(M x L), 탐색 시간 복잡도는 O(L)이다.
제일 긴 문자열의 길이를 L이라 하고, 총 문자열들의 수를 M이라 할 때 시간 복잡도는 위와 같다.
생성 시간 복잡도는 모든 문자열 M 개를 넣어야 하고,
M 개에 대해서 트라이에 넣는 건 가장 긴 문자열 길이인 L 만큼 걸리므로 O(MxL)의 시간 복잡도를 가진다. (삽입은 O(L)이다.)
탐색 시간 복잡도는 트리를 제일 깊게 탐색하는 경우는 가장 긴 문자열 길이인 L까지 깊게 들어가는 것이므로 O(L)의 시간 복잡도를 가진다.
트라이(Trie) 구현 (C++)
#include <iostream>
#include <unordered_map>
using namespace std;
// TrieNode클래스를 사용하여 Trie의 각 노드를 표현
class TrieNode {
public:
unordered_map<char, TrieNode*> children;
bool isEndOfWord;
TrieNode() {
isEndOfWord = false;
}
};
// Trie 클래스
class Trie {
// Trie의 루트 노드에 대한 포인터인 Trie개인 멤버 변수
private:
TrieNode* root; // 루트 노드
// 생성자새 인스턴스를 만들고 Trie를 초기화합
public:
Trie() {
root = new TrieNode();
}
// 문자열을 받아 Trie에 추가합니다.
// 루트 노드에서 시작하여 Trie 아래로 이동하여 단어의 각 문자에 필요한 새 노드를 만듭니다.
void insert(string word) {
TrieNode* curr = root; // 시작
for (char c : word) {
if (curr->children.find(c) == curr->children.end()) {
// Trie에 없다면 새 노드 생성
curr->children[c] = new TrieNode();
}
curr = curr->children[c]; // Trie에 이미 존재하는 경우 기존 노드로 이동
}
// 단어의 끝을 나타내는 isEndOfWord bool값
curr->isEndOfWord = true;
}
// 단어를 검색합니다.
bool search(string word) {
TrieNode* curr = root;
for (char c : word) {
if (curr->children.find(c) == curr->children.end()) {
return false;
}
curr = curr->children[c];
}
return curr->isEndOfWord;
}
// prefix(접두사)로 시작하는 단어가 Trie에 있는지 확인
bool startsWith(string prefix) {
TrieNode* curr = root;
for (char c : prefix) {
if (curr->children.find(c) == curr->children.end()) {
return false;
}
curr = curr->children[c];
}
return true;
}
};
int main() {
Trie trie;
trie.insert("hello");
trie.insert("world");
trie.insert("hello world");
cout << trie.search("hello") << "\n"; // output: 1 (true)
cout << trie.search("hello world") << "\n"; // output: 1 (true)
cout << trie.search("hi") << "\n"; // output: 0 (false)
cout << trie.startsWith("hell") << "\n"; // output: 1 (true)
cout << trie.startsWith("heaven") << "\n"; // output: 0 (false)
return 0;
}
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
// TrieNode클래스를 사용하여 Trie의 각 노드를 표현
class TrieNode {
public:
unordered_map<char, TrieNode*> children;
int num; // 연관된 단어의 개수를 저장
TrieNode() {
num = 0;
}
};
// Trie 클래스
class Trie {
private: // Trie의 루트 노드에 대한 포인터인 Trie개인 멤버 변수
TrieNode* root; // 루트 노드
public:
Trie() { // 생성자새 인스턴스를 만들고 Trie를 초기화
root = new TrieNode();
}
// 문자열을 받아 Trie에 추가합니다.
// 루트 노드에서 시작하여 Trie 아래로 이동하여 단어의 각 문자에 필요한 새 노드를 만듭니다.
void insert(string word) {
TrieNode* curr = root; // 시작
for (char c : word) {
if (curr->children.find(c) == curr->children.end()) {
// Trie에 없다면 새 노드 생성
curr->children[c] = new TrieNode();
}
// Trie에 이미 존재하는 경우 기존 노드로 이동
curr = curr->children[c];
curr->num++; // 연관된 단어의 개수 추가
}
}
// 단어를 검색합니다.
// 연관된 단어의 개수가 1이라면 글자수 반환
int search(string word) {
TrieNode* curr = root;
int cnt = 0;
for (char c : word) {
curr = curr->children[c];
cnt++;
if (curr->num == 1) {
// 연관된 단어의 개수가 1이라면
// 자동완성
return cnt;
}
}
return 9999; // 문제에서 나올 수 없는 경우
}
// prefix(접두사)로 시작하는 단어가 Trie에 있는지 확인
int startsWith(string prefix) {
TrieNode* curr = root;
for (char c : prefix) {
if (curr->children.find(c) == curr->children.end()) {
return false;
}
curr = curr->children[c];
}
return curr->children.size();
}
};
int solution(vector<string> words) {
int answer = 0;
Trie trie;
for (auto& it : words) {
trie.insert(it);
}
for (auto& it : words) {
if (trie.startsWith(it) >= 1) {
// 접두사로 시작하는 단어가 있다면
// 단어 전체를 입력해야한다.
answer += it.length();
continue;
}
// 자동완성 확인
answer += trie.search(it);
}
return answer;
}
https://www.acmicpc.net/problemset?sort=ac_desc&algo=79 <- 트라이 연습 문제 모음


