
Unity DOTS에 대하여
Data-Oriented Technology Stack (데이터 지향 기술 스택)
개요
Unity DOTS는 하드웨어 특성과 제약 조건을 최대한 활용할 수 있도록 지원하는 소프트웨어 아키텍처
OOP(객체 지향 프로그래밍) 접근 방식과 달리 DOD(데이터 지향 디자인)를 사용하며 코드와 데이터에 중점을 둔 접근 방식
DOTS를 사용하면 멀티코어 프로세서를 활용하여 데이터 처리를 병렬화할 수 있음
기능 및 패키지
C# Job 시스템
멀티 스레드 코드를 쉽고 안전하게 작성함으로써 최신 CPU의 수많은 코어를 활용
버스트 컴파일러
Mono나 ILCPP보다 훨씬 빠른 코드를 생성하는 최적화 C# 컴파일러
Unity.Mathematics
버스트 컴파일된 코드에서 사용할 때 특별히 최적화된 수학 라이브러리를 제공
Unity.Collections
List, HashMap 같은 일반적인 컬렉션 유형을 제공하며 버스트 컴파일된 코드에서 사용됨
일반 C# 컬렉션과는 다르게 관리되고 Job에서 안전하게 사용될 수 있도록 안전성 검사를 지원
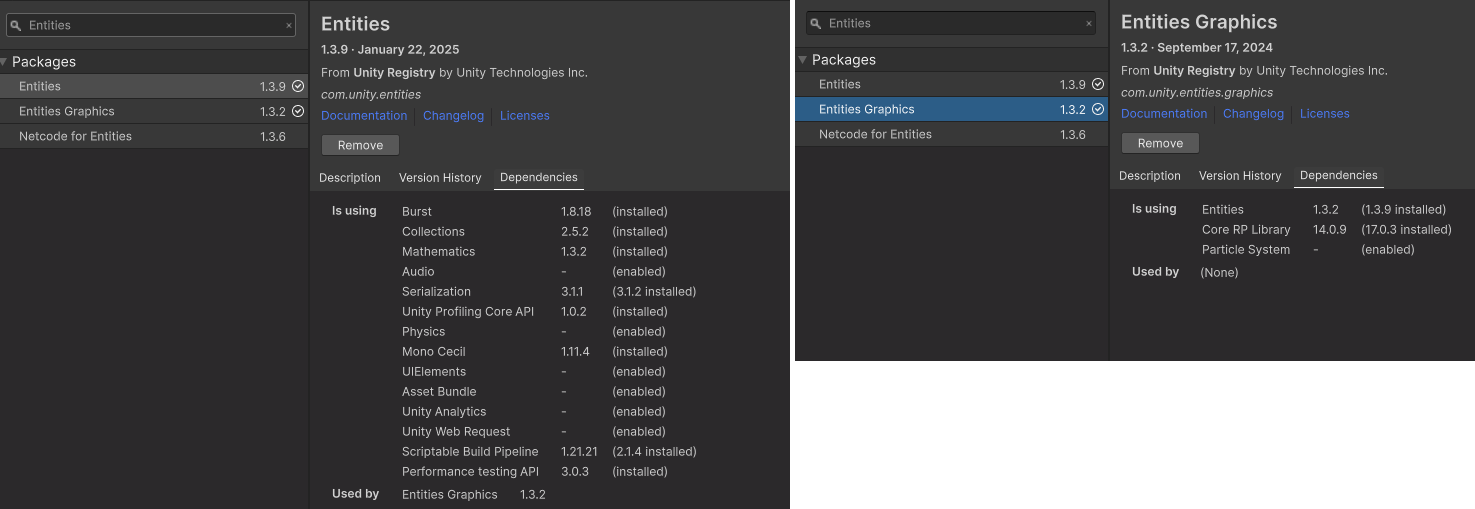
Unity.Entities
ECS(엔티티 컴포넌트 시스템) 아키텍처의 형태를 제공
즉, 엔티티는 게임 오브젝트보다 가볍고 효율적인 대체제이며 시스템이라는 코드 단위로 처리됩니다.
Unity.Entities.Graphics
URP(유니버설 렌더 파이프라인) 또는 HDRP(고해상도 렌더 파이프라인)를 사용하여 엔티티를 렌더링
[번외 1]
Unity.Physics
결정론적 리지드바디 동역학 시스템과 공간 쿼리 시스템을 제공
Unity.Netcode 패키지(Netcode for Entities라고도 함)
권한 서버와 클라이언트측 예측이 포함된 네트워크 멀티플레이어 기능을 제공
[번외 2 – 20250123]
Unity에서는 현재 애니메이션, 오디오, UI에 대한 완전한 엔티티 기반 솔루션을 제공하지 않기 때문에,
엔티티 기반 프로젝트에서 해당 기능을 구현하려면 기존의 게임 오브젝트나 다른 대안에 의존해야 합니다.
예를 들어, 애니메이션이 적용된 몬스터가 등장하는 엔티티 기반 게임을 제작할 경우,
시뮬레이션 로직에서는 몬스터를 엔티티로 표현하더라도 최종적으로는 게임 오브젝트를 사용해 렌더링해야 합니다.
이를 위해 각 몬스터 엔티티와 해당 게임 오브젝트 간의 상태를 동기화해야 하며, 이러한 방식은 프로젝트 규모가 크지 않다면 허용 가능한 수준의 오버헤드로 간주될 수 있습니다.
DOTS의 주요 개념
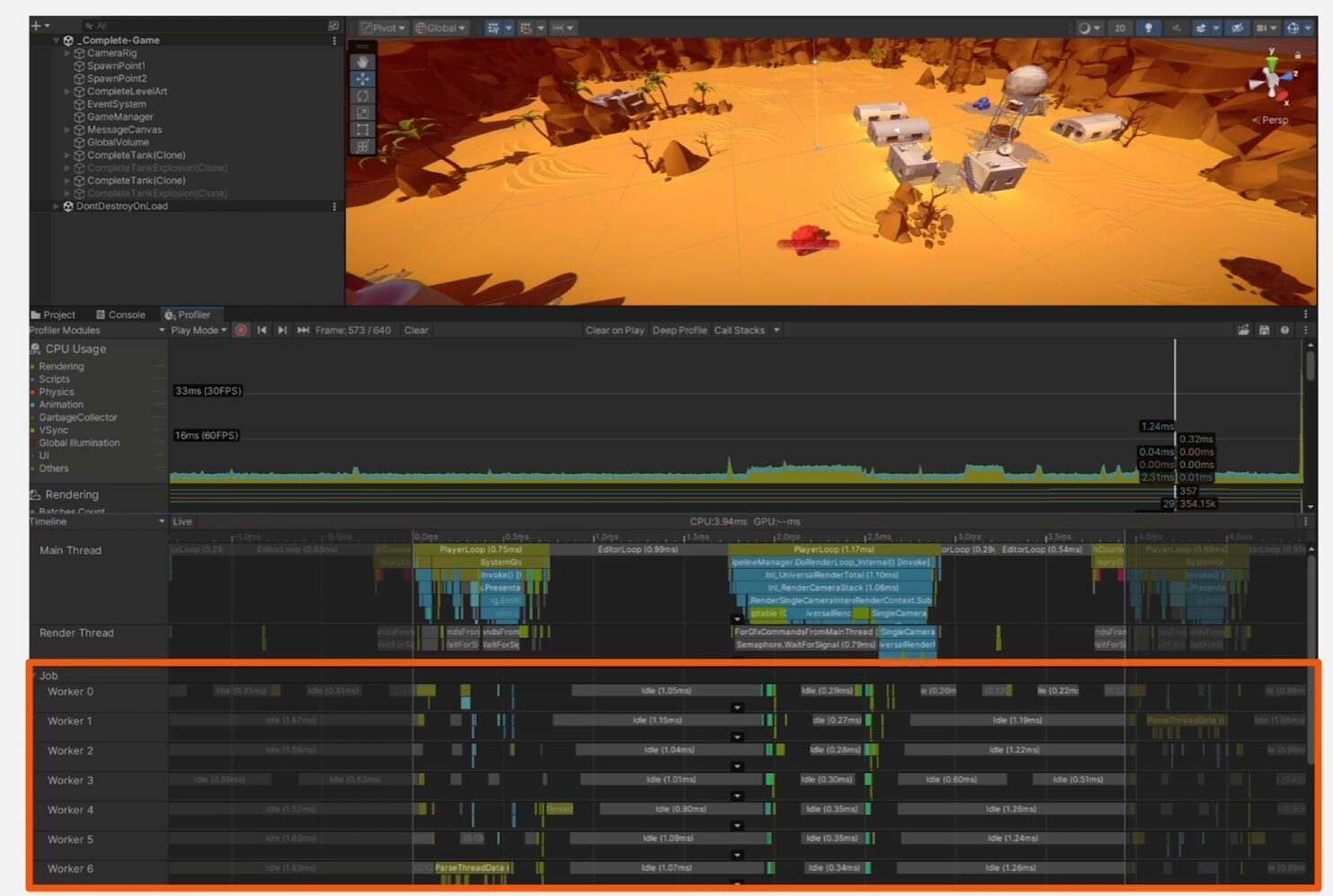
Unity 프로파일러를 보면 Main Thread 외에도 추가적인 Worker Thread를 생성한다

예를 들어 해당 환경은 코어가 8개 있는 컴퓨터에서 실행 중이기 때문에 7개의 Worker Thread가 존재
Worker Thread는 유니티 내부에서 사용되지만 C#의 Job System을 이용하면 Worker Thread에서도 자체 고유 코드를 실행할 수 있음
(Job은 Worker Thread에서 실행되는 작업 단위 )

위와 같은 예를 보면 Job은 IJob 인터페이스를 구현하는 구조체 유형으로 정의되는데
이 인터페이스에는 Execute라는 하나의 필수 메서드가 있고 해당 메서드는 Worker Thread 중 하나에서 Job이 실행될 때 호출된다.
NativeArray<int> Nums 배열은 일반적인 C#으로 관리되는 배열이 아니며 Unity API의 관리되지 않는 네이티브 배열입니다.
Job에서 관리되는 오브젝트를 사용하는 게 아예 불가능하지는 않지만 안전한 사용을 위해서는 특별한 주의가 필요하기 때문에
보통은 Job에서 관리되는 오브젝트에 액세스하지 않도록 해야 합니다
또한 Burst Compiler된 코드에서는 관리되는 오브젝트가 결코 허용되지 않기 때문에 Burst Compiler의 장점을 활용하려면
Unity의 Job System과 Burst Compiler에서 관리되는 오브젝트(Managed Object)의 사용을 제한해야합니다.

먼저 Job의 인스턴스를 생성하고 Nums 필드를 제곱하려는 숫자 배열로 설정한 다음
Job 인스턴스를 글로벌 Job 대기열에 넣는 Schedule이라는 확장 메서드를 호출합니다.
그리고 일정 시점 후에 대기 상태의 Worker Thread가 더 많은 Job을 찾기 위해 대기열을 확인하고
Schedule 메서드로 대기열에 들어간 해당 Job 인스턴스를 대기열에서 가져와서 실행할 수 있습니다.
잡을 예약한 후에 일정 시점에 Main Thread는 Schedule에 의해 반환된 Job handle에서 Complete를 호출해야 합니다.
Complete를 호출하면 몇 가지 작업이 수행되는 데
만약 Complete를 호출하기 전에 Job 실행이 완료되지 않은 경우 Complete는 잡이 완료될 때까지 대기합니다.
어떤 경우에도 Complete 메서드는 잡이 실행을 완료할 때까지 반환하지 않습니다.
Complete는 Main Thread와 Job을 동기화하기 위해 사용되고 Main Thread는 작업 완료가 필요할 때 예약된 잡에서 Complete를 호출합니다
Complete가 수행하는 다른 중요한 일은 Job 대기열에서 모든 Job의 기록을 제거하는 것 입니다.
리소스 유출을 막으려면 예약된 모든 잡을 완료해야 하기 때문입니다
추가적으로 주의가 필요한 제한이 있는데 Job을 예약하고 완료할 수 있는 것은 오직 Main Thread이고
Main Thread가 현재 예약된 Job에서 사용 중인 데이터에 액세스해서는 안 된다는 것입니다(네이티브에 접근하지 말 것)
Main Thread는 Job이 완료된 이후에 배열에 내용에 접근하는 것이 안전합니다.

잡을 두 번 인스턴스화해서 두 Job의 Nums 필드를 동일한 네이티브 배열로 설정하고
그런 다음 두 잡을 예약하려고 하면 두 번째 Schedule 호출에서 안전성 검사 예외가 발생합니다.
두 Job이 동일한 유형의 인스턴스라는 것은 부수적인 사실이며 문제와 관계 없습니다.
문제는 예약하려는 두 번째 잡이 이미 예약된 잡과 똑같은 배열에 액세스하려고 한다는 겁니다.
동일한 데이터에 액세스하는 두 Job을 동시에 실행할 수 있도록 허용하면
경쟁 상태가 되기 때문에 이미 예약된 잡에서도 사용 중인 데이터에 새 Job이 액세스하는 경우
Schedule 메서드의 안전성 검사에서 예외 오류가 발생합니다.
종속성을 이용한 해결
해결법 1.

해결법 2.

일반적으로 Worker Thread는 Job의 모든 종속성이 실행을 완료할 때까지 대기열에서 Job을 가져오지 않고
안전성 검사는 Job이 자체 종속성과 충돌하지 않는다는 것을 압니다
실질적으로 Job 종속성을 사용하면 필요할 때 Job 간의 실행 순서를 설정할 수 있습니다.
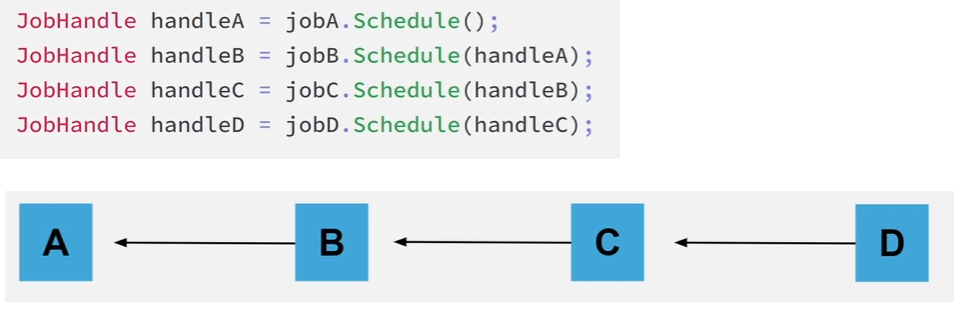
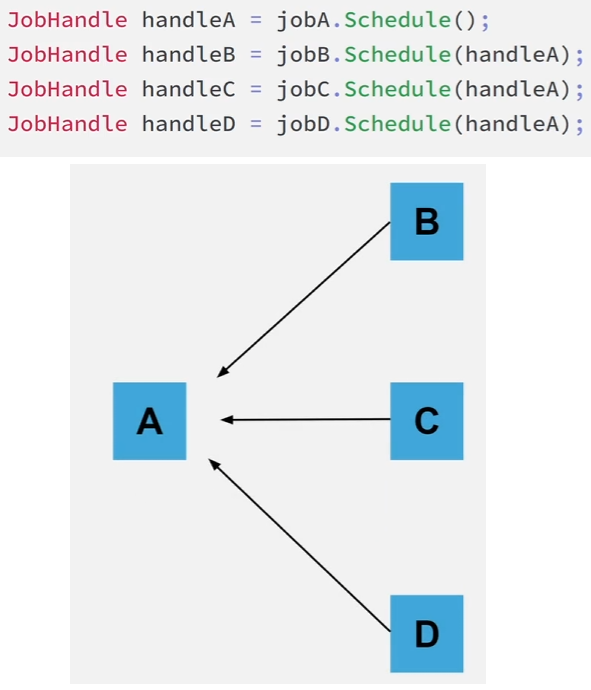
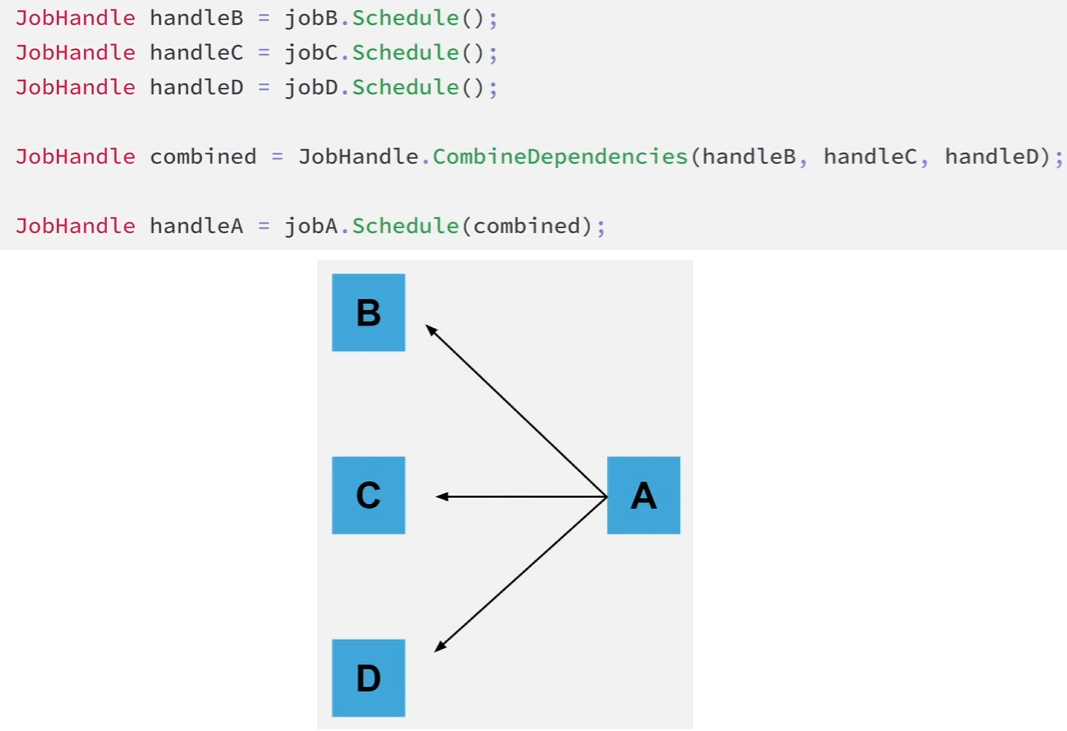
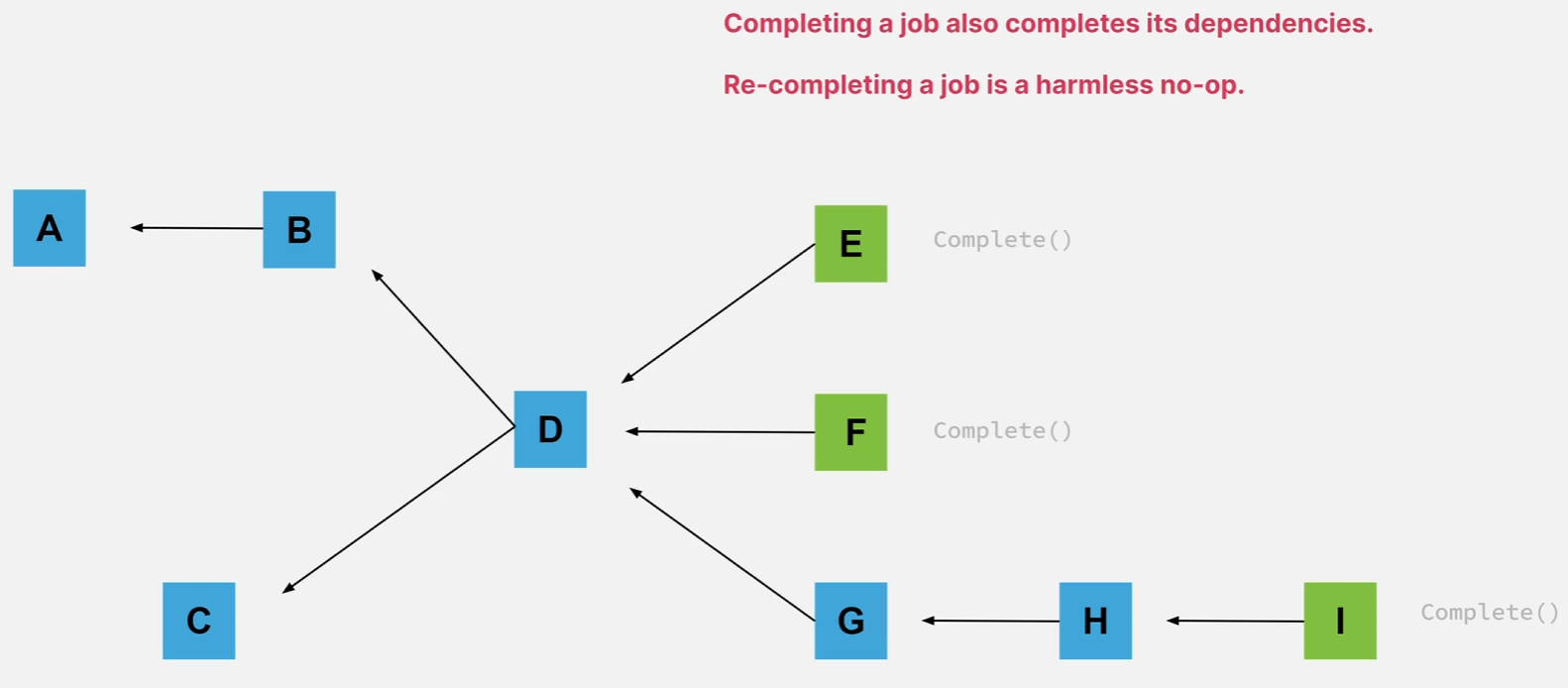
특정 Job을 완료하면 그에 종속된 Job도 모두 재귀적으로 완료된다는 것을 알아야 합니다.
즉, 이 그래프에서는 모든 개별 Job의 핸들에 대해 Complete를 호출할 필요는 없고 E, F, I의 핸들만 호출하면 된다는 뜻입니다.
또한 이미 완료된 잡에 대해 Complete를 호출하더라도 문제가 없기 때문에 중복 완료에 대해 걱정할 필요는 없습니다.
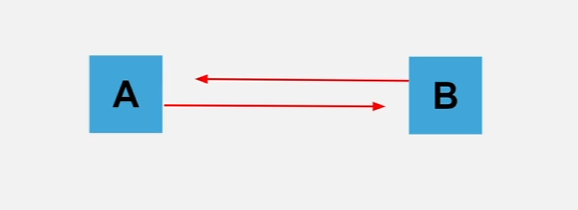
순환 Job 종속성을 생성하면 교착 상태가 발생할 수 있기 때문에 생성하지 않는 게 좋습니다.
다행히도 그러한 경우는 걱정할 필요가 없습니다.
왜냐하면 Job은 자신보다 먼저 예약된 Job에만 종속될 수 있고
한 번 예약된 Job은 종속성을 변경할 수 없기 때문입니다.
또한 이 두 가지 특성이 함께 작용하기 때문에 순환 종속성 예약은 불가능합니다.
Job 병렬 처리

잡이 처리하는 배열이나 목록의 요소를 병렬로 처리할 수 있습니다.
예를 들어 SquaresJob에서는 배열의 요소를 서로 동시에 모두 안전하게 제곱하려고 한다면 여러 개의 다른 잡으로 수동 분할할 수도 있습니다.
위에 대한 솔루션으로 IJobParallelFor 인터페이스를 사용하면 좋습니다
이 IJobParallelFor가 실행될 때 Execute 메서드는 배열의 각 인덱스마다 한 번씩 호출되는데
각 호출은 하나의 요소만 즉 int 파라미터로 전달된 인덱스의 요소만 처리합니다.
배열의 인덱스에 다른 값이 전달되면 안전성 검사 예외 오류가 발생합니다.

IJobParallelFor를 예약할 때는 배열 길이와 배치 크기를 전달합니다.
예를 들어 위의 예시의 배열 길이가 250이고 배치 크기가 100인 경우 Job은 3개의 배치로 나누어집니다.
첫 번째는 인덱스 0부터 99까지 처리하고
두 번째 배치는 인덱스 100부터 199까지 처리하고
마지막 배치는 나머지 인덱스 200부터 249까지 처리합니다.
Job이 3개의 배치로 나뉘었기 때문에 최대 3개의 Worker Thread를 통해 효과적으로 처리됩니다.
배치 크기는 각 프로젝트에서 실험을 통해 각 특정 Job에 대한 최적의 크기를 찾아야 합니다.
주의할 점은 작은 배치가 너무 많아지면 Job 시스템에 상당한 오버헤드가 발생할 수 있다는 점에 유의해야 합니다.
가장 중요한 오버헤드로 메모리 액세스 문제가 있습니다.
만약 워크로드를 8개 코어로 분산시키면 8개의 코어는 모두 메모리 액세스를 위해 서로 경쟁해야 하기 때문에 문제가 발생합니다.
8개의 코어가 배열을 읽고 쓰는 속도가 1개의 코어보다 더 빠를 수 없다는 것이 메모리 액세스 오버헤드를 피하는 포인트 입니다.
따라서 작업이 가벼운 경우에는 단일 스레드 잡을 사용하는 것이 더 좋습니다.
반대로 메모리 액세스의 바이트당 계산이 더 많이 필요한 경우에는 작업의 병렬화를 통해 성능을 크게 향상시킬 수 있습니다.
ECS Entity와 Component
Job과 Unity GameObject의 호환성 문제

게임 오브젝트는 클래스 유형이고 컴포넌트를 위한 컨테이너입니다.
일반적으로 모든 게임 오브젝트는 항상 Transform 컴포넌트를 가지고 있고
계층적으로 다른 게임 오브젝트의 부모로 지정될 수 있습니다.
게임 오브젝트 컴포넌트는 그 자체로 클래스 유형이고 다른 관리되는 오브젝트에 대한 레퍼런스를 포함할 수도 있습니다.
Monobehaviour의 Update()와 같은 컴포넌트의 특정 메서드는 Unity 게임 루프의 특정 지점에서 호출됩니다.

주요 성능 문제는 게임 오브젝트와 컴포넌트가 관리되는 오브젝트이기 때문에
버스트 컴파일된 코드에서 사용할 수 없고 특별히 가공한 Job에서만 사용할 수 있다는 점입니다
관리되는 오브젝트는 가비지 컬렉션 오버헤드를 유발하고 생성과 파괴 비용도 그다지 저렴하지 않다는 점도 이상적할 수 없습니다.
마지막으로, 관리되는 다른 오브젝트처럼 게임 오브젝트와 컴포넌트는 메모리 주변에 분산되어 있습니다
배열에 깔끔하게 패킹되어 있지 않으며 분산된 오브젝트를 순회하는 것은 비효율적인 경향이 있습니다.
캐시 부적중이 발생할 수 있고 시스템 자원의 비용이 들기 때문입니다.
Entity Component System
위의 상황을 방지하기 위해 게임 오브젝트 대신 Entity를 사용할 수 있습니다.
Entity는 ID 번호이며 ID는 여러 컴포넌트와 연결될 수 있습니다.
유일한 제한은 단일Entity가 특정 유형의 여러 컴포넌트를 가질 수 없다는 것입니다.
가령 컴포넌트 유형 Foo가 주어진 경우 단일 Entity는 Foo 컴포넌트 하나만 가질 수 있습니다.
게임 오브젝트와의 또 다른 차이점은 Entity에는 부모 지정 개념이 빌트인되어 있지 않다는 것입니다.

게임 오브젝트의 컴포넌트와 달리 Entity의 컴포넌트는 일반적으로 IComponentData 인터페이스를 구현한 구조체로 정의되는 관리되지 않는 오브젝트입니다.
이 IComponentData 인터페이스에는 메서드가 없지만 효과적으로 구조체를 컴포넌트 유형으로 표시합니다.
IComponentData 구조체에는 int, float나 Entity ID 형식의 레퍼런스 등 관리되지 않는 데이터 유형만 포함될 수 있습니다.
실제로 클래스에 IComponentData를 적용하여 관리되는 컴포넌트 유형을 정의할 수 있습니다.
그런 컴포넌트 유형은 다른 관리되는 오브젝트를 포함할 수 있습니다.
하지만 관리되는 컴포넌트 유형은 게임 오브젝트의 모든 효율성 문제를 안고 있기 때문에 반드시 필요할 때만 사용해야 합니다
관리 여부에 상관없이 Entity의 컴포넌트는 일반적으로 순수한 데이터이기 때문에
보통 Entity의 컴포넌트에는 메서드가 주어지지 않습니다. (금지는 아님)
마지막으로, 나중에 설명하겠지만 Entity와 컴포넌트는 긴밀하게 패킹된 배열에 저장되기 때문에
대량으로 쿼리를 호출해서 액세스하는 것이 효율적입니다.

컴포넌트 유형으로 IComponent Data를 구현하는 Movement 구조체를 예시를 살펴보면
구조체에는 2개의 관리되지 않는 필드인 float3 Direction과 float Speed가 있습니다.
참고로 float3는 Mathematics 패키지에 정의되어 있습니다
vector3처럼 float3는 3개의 플로트를 x, y, z에 저장합니다.
World와 EntityManager
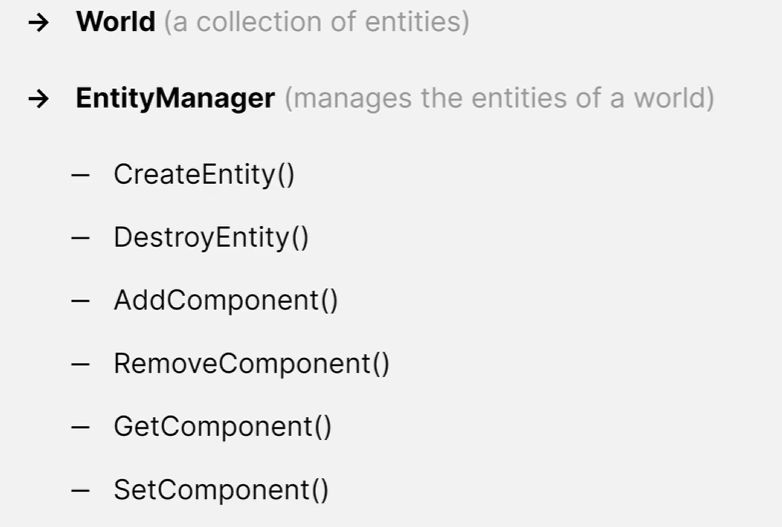
Entity를 생성하려면 먼저 Entity의 컨테이너인 Wolrd가 필요합니다.
하나의 Wolrd 안에 있는 모든 Entity는 해당 Wolrd 내에서 고유한 ID를 갖지만 (서로 다른 배열의 인덱스처럼)
다른 Wolrd 의 엔티티가 동일한 ID를 가질 수 있으므로 잘못된 Wolrd 에서 ID로 엔티티를 찾지 않도록 주의해야 합니다.
대부분의 경우 하나의 Wolrd 만 필요하겠지만 논리적 분리가 필요한 경우에는 추가 Wolrd 를 생성하는 것이 유용할 수 있습니다.
예를 들어 DOTS Netcode 패키지는 서버와 각 클라이언트에 대해 별도의 Wolrd를 생성합니다.
Wolrd 의 EntityManager는 Entity를 생성, 파괴하고 컴포넌트를 추가, 제거하고 컴포넌트 값을 받고 설정하는 메서드를 제공합니다.

Wolrd의 Entity는 Archetype으로 나뉘는데 이때 각 Archetype은 모든 엔티티를 컴포넌트 유형의 특정 조합으로 저장합니다.
각 Archetype 내에서 Entity와 컴포넌트는 Chunk라고 하는 균일한 크기의 메모리 블록에 저장됩니다.
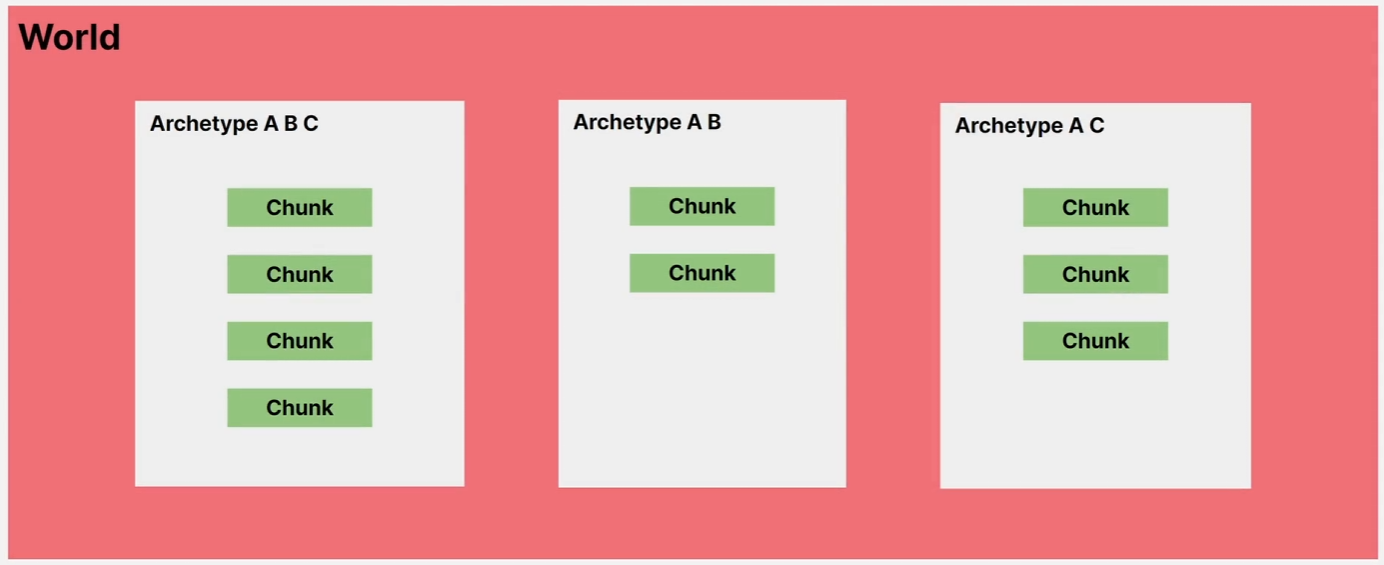
예를 들어 여기 3개의 Archetype이 있는 단일 World가 있습니다.
왼쪽의 Archetyp은 4개의 Chunk를 가지고 있고 컴포넌트 유형이 A, B, C인 모든 Entity를 저장합니다.
가운데 Archetype은 2개의 Chunk를 가지고 있고 컴포넌트 유형이 A, B인 모든 Entity를 저장합니다.
오른쪽의 Archetype은 3개의 Chunk 타입에 컴포넌트 유형이 A, C인 모든 Entity를 저장하죠.
이 구조의 의미는 Entity에서 컴포넌트를 추가하거나 제거하려면 새로운 Archetype으로 Entity를 옮겨야 한다는 겁니다.
예를 들어 컴포넌트 유형이 A, B인 Entity의 경우 C 유형의 컴포넌트를 추가하면
Archetype이 A와 B인 현재 Chunk에서 Archetype이 A, B, C인 Chunk로 해당 Entity를 옮겨야 합니다.
다행히도 이 작업을 수동으로 처리할 필요는 없습니다.
사용자로서 EntityManager 메서드를 호출한 다음 엔티티를 생성, 삭제하고 컴포넌트를 추가, 제거만 하면 됩니다.
EntityManager는 Archetype의 생성과 Chunk 생성, 파괴, Chunk 간 Entity 이동에 대한 모든 세부 사항을 처리합니다.
참고로 Archetype과 Chunk를 수정하는 이러한 작업을 구조적 변경 작업이라고 합니다.
반면, 저장된 컴포넌트 값을 단지 읽고 수정하는 것은 구조적 변경 작업이 아닙니다.
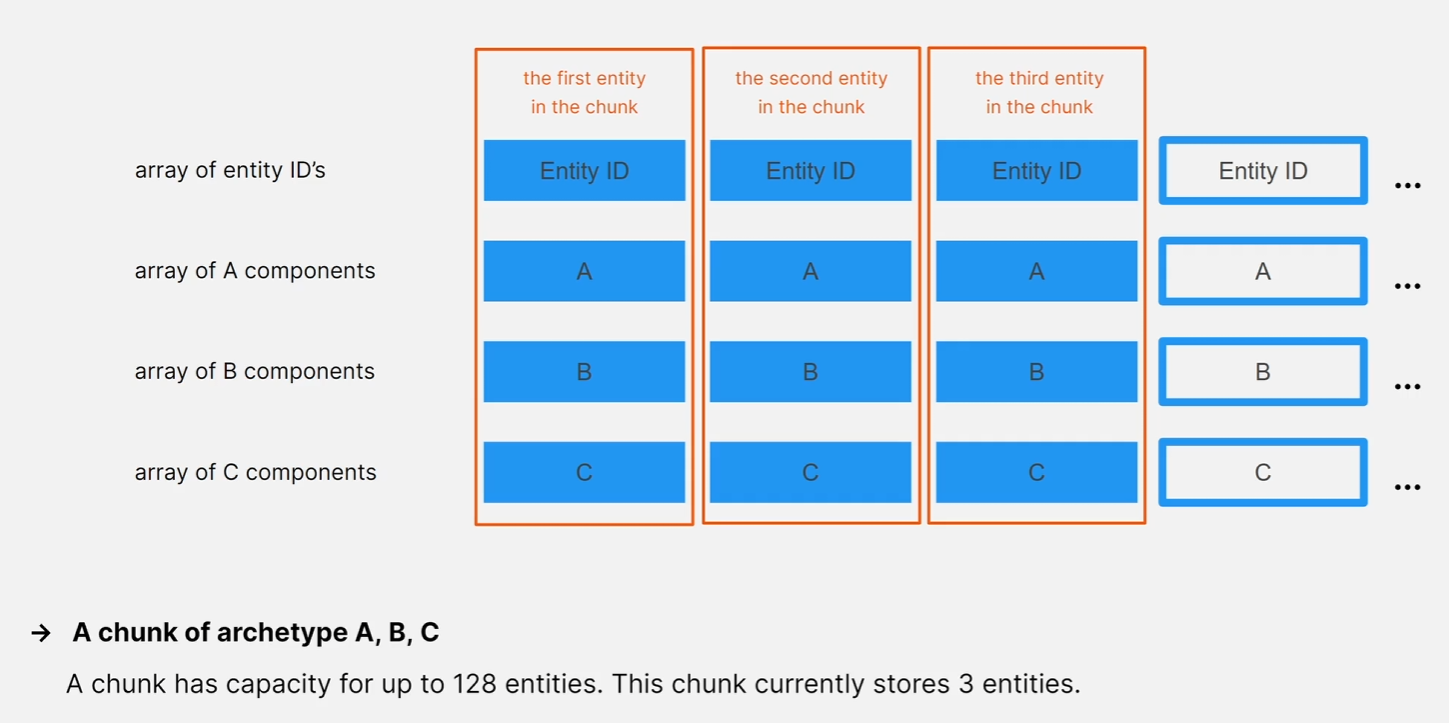
Chunk 자체의 구조를 살펴보면 위와 같은 예시로 컴포넌트 유형이 A, B, C인 Archetype의 Chunk 다이어그램이 있다고 한다면
각 청크에 들어갈 수 있는 Entity의 수는 컴포넌트 유형의 수와 크기에 따라 달라지지만 Chunk당 Entity 수는 항상 128개로 제한됩니다.
이 예에서는 Chunk가 128개의 Entity를 수용할 수 있지만 현재는 3개의 엔티티만 저장하고 있다고 가정해 봅시다.
이 Chunk의 Archetype에는 세 가지의 컴포넌트 유형이 있으므로 이 Chunk는 총 4개의 배열로 구성됩니다.
각 컴포넌트 유형마다 하나씩 그리고 엔티티 ID용 배열 하나 (ID, A, B, C)
첫 번째 Entity와 컴포넌트는 이 배열의 인덱스 0에 저장되고
두 번째는 인덱스 1에, 세 번째는 인덱스 2에 저장됩니다.
일반적으로 Chunk에 저장된 엔티티는 항상 배열의 시작 부분부터 긴밀하게 패킹됩니다.
이 상태를 유지하기 위해 Chunk에 추가된 Entity는 항상 첫 번째 빈 슬롯에 배치되고 Entity가 제거되면 마지막 Entity가 빈 공간을 채우기 위해 옮겨집니다.
예를 들어 첫 번째 슬롯의 Entity를 제거하면 마지막 Entity가 첫 번째 슬롯을 채우기 위해 옮겨집니다.

추가적으로 컴포넌트 유형은 모든 크기가 될 수 있기 때문에
Chunk의 컴포넌트 배열은 항상 동일한 수의 슬롯을 갖지만 각각 Chunk의 크고 작은 부분을 차지할 수 있습니다.
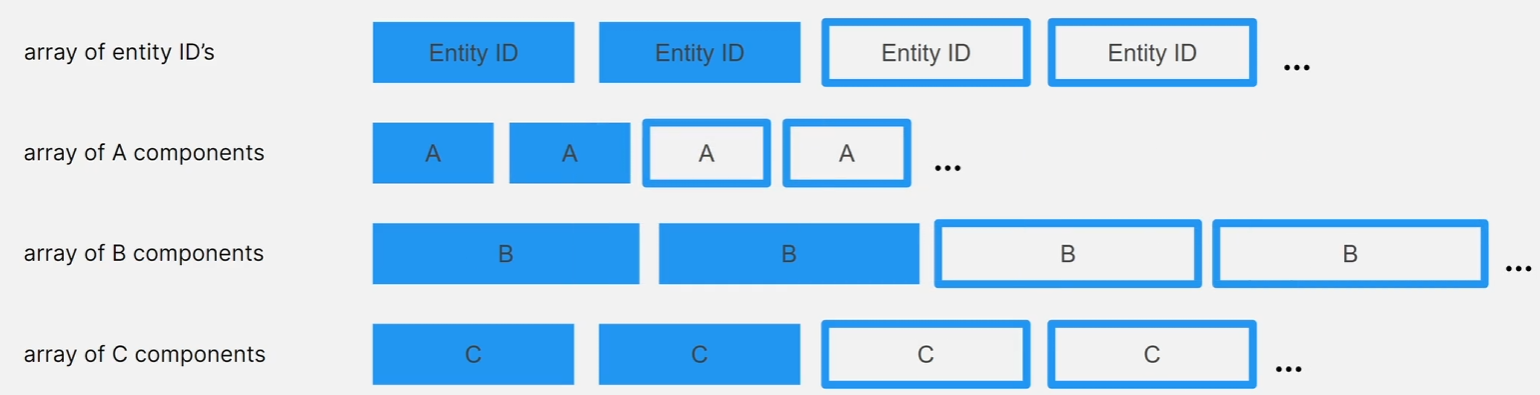

ID로 Entity를 찾을 수 있게 하려면 World의 EntityManager가 Entity 메타데이터의 배열을 유지해야 합니다.
각 Entity ID에는 이 메타데이터 배열의 슬롯을 나타내는 인덱스 값이 있고
해당 슬롯에는 해당 Entity가 저장된 Chunk를 가리키는 포인터와 해당 Chunk 안에 있는 Entity의 인덱스가 저장됩니다.
특정 인덱스에 해당하는 Entity가 없는 경우 해당 인덱스의 Chunk 포인터는 null입니다.
Entity가 파괴된 후 Entity 인덱스를 재사용할 수 있도록 각 Entity ID에는 버전 번호도 포함됩니다.
예를 들어 인덱스가 1, 2, 5인 Entity가 현재 존재하지 않기 때문에 해당 슬롯의 Chunk 포인터는 모두 null입니다.

Entity가 파괴되면 해당 인덱스에 저장된 버전 번호가 증가합니다.
따라서 ID의 버전 번호가 현재 저장된 번호와 일치하지 않는 경우 해당 ID는 이미 파괴된 Entity를 참조하거나 존재하지 않는 Entity를 참조해야 합니다.

Entity 쿼리를 사용하면 지정된 컴포넌트 유형 집합을 가진 모든 Chunk 목록을 효율적으로 검색할 수 있습니다.
예를 들어 컴포넌트 유형이 A, C인 모든 Chunk를 찾는 쿼리는
왼쪽과 오른쪽 Archetype의 모든 Chunk와 일치하지만 컴포넌트 유형 C가 없으니 가운데 Chunk는 일치하지 않습니다.
일부 경우에는 특정 컴포넌트 유형을 가진 Chunk를 필터링하는 쿼리를 사용할 수 있습니다.
예를 들어 컴포넌트 A, C를 포함하고 B는 포함하지 않는 쿼리는 오른쪽 Archetype의 Chunk만 일치합니다.

Job에서 Entity와 컴포넌트에 액세스하려면 두 가지 특수 Job 유형인 IJobChunk와 IJobEntity를 사용할 수 있습니다.
IJobChunk의 경우 schedule 메서드에 쿼리를 전달하고 쿼리가 실행될 때 쿼리와 일치하는 모든 Chunk에서 Job이 반복된 다음
해당 Job이 각 Chunk에서 개별 Entity와 컴포넌트에 액세스할 수 있습니다.
IJobEntity도 동일한 방식으로 작동하지만 Chunk보다는 개별 Entity에서 직접 반복 작업을 수행합니다.
일반적으로 IJobChunk는 조금 불편할 수 있지만 명시적으로 낮은 수준의 컨트롤을 제공합니다.
IJobEntity는 일부 보일러 플레이트 코드를 작성하기 위해 소스 생성에 의존하기 때문에 더 간단하고 더 편리하지만
(보일러플레이트 – 여러 가지 상황에서 거의 또는 전혀 변경하지 않고 재사용)
IJobEntity가 일부 특정한 사용 사례를 지원하지 않기 때문에 때로는 IJobChunk를 사용해야 할 수 있습니다.

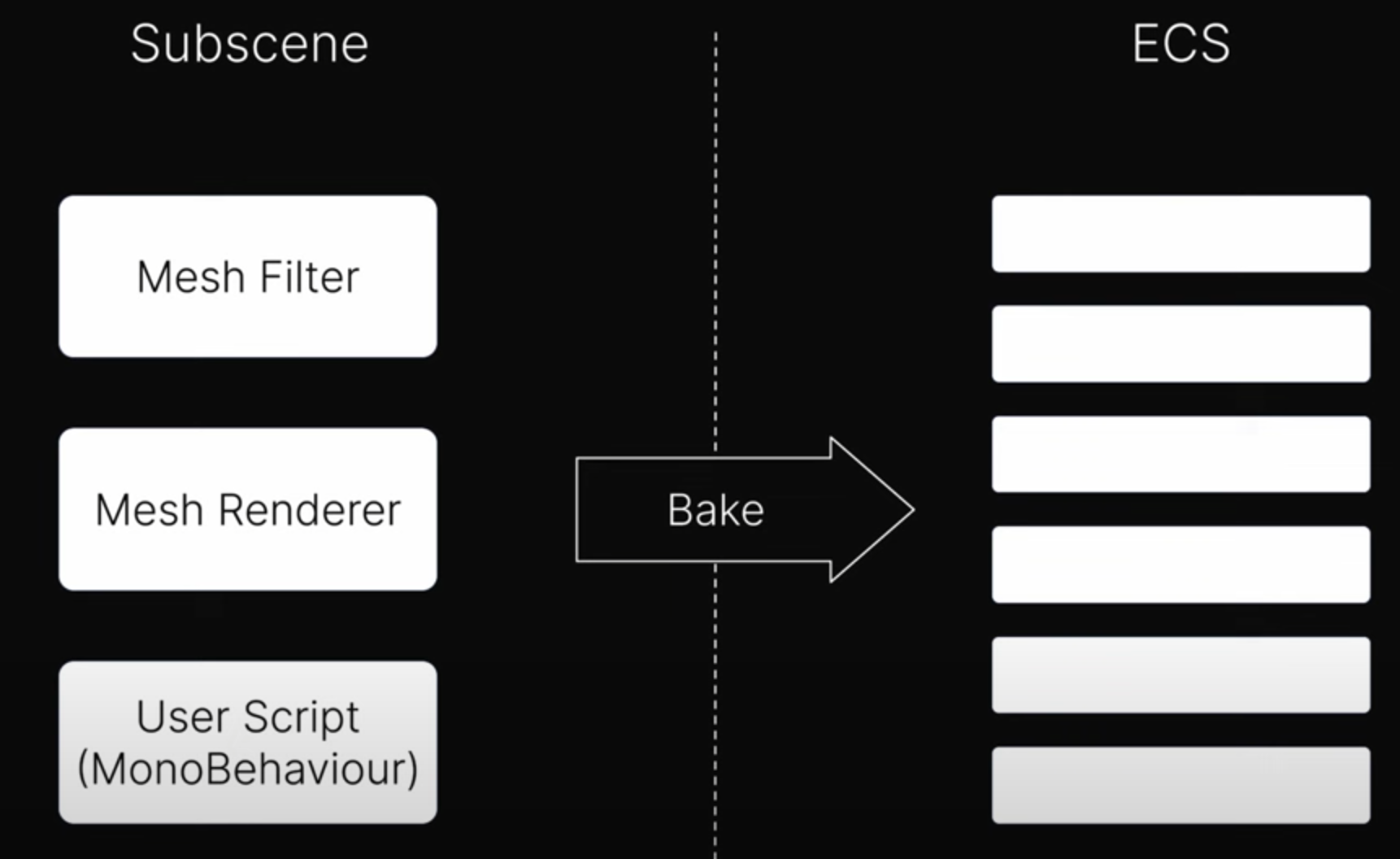
마지막으로 Entity는 Unity 씬에 직접 포함될 수 없지만 Baking이라는 빌드 시간 프로세스가 하위 씬의 게임 오브젝트를 Entity로 전환합니다.
간단히 말하면 Baking은 하위 씬의 각 게임 오브젝트마다 하나의 Entity를 생성하고
각 게임 오브젝트의 각 컴포넌트는 Entity의 컴포넌트 값이 추가되고 설정되는 Baker 클래스에 의해 처리됩니다.
이렇게 생성된 Entity 집합은 전체를 포함하는 씬 자체가 로드될 때 런타임 시 로드되는 Entity 씬 파일로 직렬화됩니다.
Bake된 Entity는 직렬화되기 전에 베이킹 시스템에서 추가로 처리될 수 있기 때문에 보다 고급적인 목적에 유용합니다.
참고 글


핑백: DOTS 정리 (3) – HelloCube로 엔티티 알아보기 - 어제와 내일의 나 그 사이의 이야기
핑백: DOTS 정리 (2) - Unity Job 시스템 시작하기 - 어제와 내일의 나 그 사이의 이야기