Repository Pattern
정의 및 목적
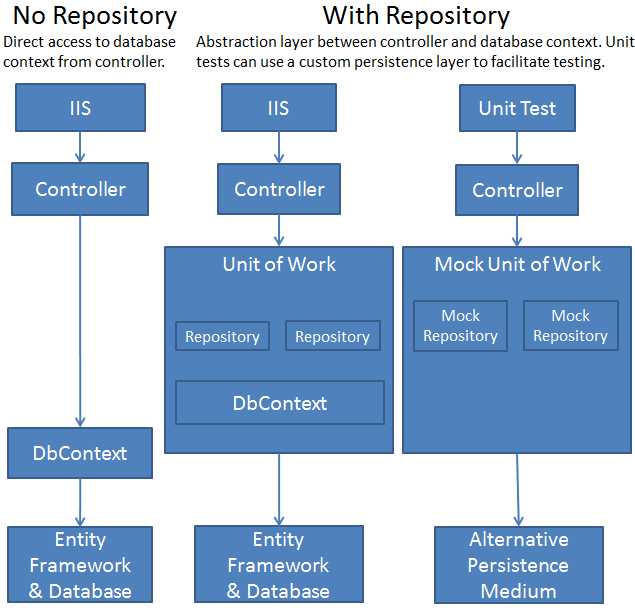
Data access logic을 business logic에서 분리하여 코드를 더 깨끗하고 유지 보수가 쉽도록 만드는데 중점을 둔 패턴
애플리케이션의 도메인 계층과 데이터 액세스 계층 간의 중간 계층을 제공하여, 데이터베이스와의 상호작용을 추상화하고 코드의 일관성을 유지
Repository Pattern은 데이터 저장소(데이터 베이스, 파일 시스템 등)와 도메인 모델 간의 연결을 처리하는 역할
이 역할은 Data access logic을 캡슐화 하고, business logic이 데이터 저장소의 구현 세부 사항에 의존하지 않도록 합니다.
- 추상화 제공:
데이터 저장소와의 상호작용을 추상화하여 비즈니스 로직이 데이터베이스의 구체적인 구현에 종속되지 않도록 합니다. - 유지 보수성 향상:
데이터 액세스 코드를 한 곳에 모아 유지 보수와 변경을 쉽게 할 수 있습니다. - 재사용성 증대:
공통적인 데이터 액세스 로직을 재사용할 수 있어 코드 중복을 줄이고 효율성을 높입니다. - 테스트 용이성 강화:
Mock Repository(가짜/모의 데이터 저장소)를 사용하여 데이터 액세스 계층을 단위 테스트할 수 있으며,
데이터 저장소와 비즈니스 로직을 독립적으로 테스트할 수 있습니다. - 일관된 데이터 액세스:
데이터 액세스 로직을 중앙 집중식으로 관리하여, 애플리케이션 전체에서 일관된 데이터 액세스 방식을 유지할 수 있습니다.
구조와 구성 요소 및 사용 예제
구성 요소는 주로 인터페이스와 이를 구현하는 클래스들로 이루어집니다.
이러한 구조는 데이터 액세스 로직을 추상화하고, 비즈니스 로직과의 분리를 명확하게 합니다.
1. 인터페이스 (Interface)
인터페이스는 데이터 액세스 로직을 추상화하여 구현 클래스가 따르는 계약을 정의합니다.
CRUD 작업(Create, Read, Update, Delete)에 대한 기본 메서드를 선언합니다.
public interface IRepository<T> where T : class
{
IEnumerable<T> GetAll();
T GetById(int id);
void Insert(T entity);
void Update(T entity);
void Delete(int id);
}
2. 구현 클래스 (Implementation Class)
구현 클래스는 인터페이스에서 선언된 메서드들을 실제로 구현합니다.
주로 Entity Framework Core와 같은 ORM을 사용하여 데이터베이스와 상호작용합니다.
public class Repository<T> : IRepository<T> where T : class
{
private readonly DbContext context;
private readonly DbSet<T> dbSet;
public Repository(DbContext context)
{
this.context = context;
this.dbSet = context.Set<T>();
}
public IEnumerable<T> GetAll()
{
return dbSet.ToList();
}
public T GetById(int id)
{
return dbSet.Find(id);
}
public void Insert(T entity)
{
dbSet.Add(entity);
context.SaveChanges();
}
public void Update(T entity)
{
dbSet.Attach(entity);
context.Entry(entity).State = EntityState.Modified;
context.SaveChanges();
}
public void Delete(int id)
{
T entity = dbSet.Find(id);
dbSet.Remove(entity);
context.SaveChanges();
}
}
3. 서비스 계층 (Service Layer)
서비스 계층은 비즈니스 로직을 포함하며, 필요에 따라 여러 리포지토리를 조합하여 데이터 작업을 수행합니다.
이 계층은 컨트롤러나 프리젠테이션 계층과 직접 상호작용합니다.
public class ProductService
{
private readonly IRepository<Product> productRepository;
public ProductService(IRepository<Product> productRepository)
{
this.productRepository = productRepository;
}
public void AddProduct(Product product)
{
productRepository.Insert(product);
}
// 다른 비즈니스 로직 메서드들도 이곳에 추가 가능
}
4. DI를 통한 주입 (Dependency Injection)
의존성 주입을 통해 리포지토리 구현체를 서비스 계층이나 컨트롤러에 주입합니다.
이를 통해 코드의 결합도를 낮추고, 테스트 용이성을 높일 수 있습니다.
public class ProductsController : ControllerBase
{
private readonly ProductService productService;
public ProductsController(ProductService productService)
{
this.productService = productService;
}
[HttpPost]
public IActionResult CreateProduct(Product product)
{
productService.AddProduct(product);
return Ok();
}
}
장점과 단점
장점
- 추상화 제공:
- 데이터 액세스 로직을 추상화하여 비즈니스 로직이 데이터 저장소의 구현 세부 사항에 의존하지 않도록 합니다.
- 이로 인해 코드의 가독성과 유지 보수성이 향상됩니다.
- 유지 보수성 향상:
- 데이터 액세스 코드를 한 곳에 모아 유지 보수와 변경을 쉽게 할 수 있습니다.
- 데이터 저장소가 변경될 때(예: SQL Server에서 MongoDB로 변경) 전체 애플리케이션을 수정할 필요 없이 리포지토리 클래스만 수정하면 됩니다.
- 재사용성 증대:
- 공통적인 데이터 액세스 로직을 재사용할 수 있어 코드 중복을 줄이고 효율성을 높입니다.
- 여러 서비스나 애플리케이션에서 동일한 리포지토리를 재사용할 수 있습니다.
- 테스트 용이성 강화:
- Mock Repository를 사용하여 데이터 액세스 계층을 단위 테스트할 수 있으며, 데이터 저장소와 비즈니스 로직을 독립적으로 테스트할 수 있습니다.
- 이는 테스트 환경에서 데이터베이스를 설정하고 관리하는 복잡성을 줄여줍니다.
- 일관된 데이터 액세스:
- 데이터 액세스 로직을 중앙 집중식으로 관리하여, 애플리케이션 전체에서 일관된 데이터 액세스 방식을 유지할 수 있습니다.
단점
- 복잡성 증가:
- 소규모 또는 단순한 애플리케이션에서는 필요 이상으로 복잡성을 추가할 수 있습니다.
- Repository Pattern을 사용하면 더 많은 파일과 클래스를 관리해야 하므로 프로젝트가 복잡해질 수 있습니다.
- 초기 설정 비용:
- 리포지토리를 설정하고 구성하는 데 시간이 걸릴 수 있습니다.
- 특히 복잡한 엔티티 간의 관계를 관리할 때 초기 설정 비용이 증가할 수 있습니다.
- 퍼포먼스 오버헤드:
- 모든 데이터 액세스가 리포지토리를 통해 이루어지므로, 직접 데이터베이스와 상호작용하는 것보다 약간의 성능 오버헤드가 발생할 수 있습니다.
- 특히 대량의 데이터를 처리하는 경우 성능 저하가 발생할 수 있습니다.
- 유연성 제한:
- 특정 데이터 액세스 요구사항이 있는 경우, 리포지토리 패턴이 충분히 유연하지 않을 수 있습니다.
- 복잡한 쿼리나 특정 데이터베이스 기능을 사용해야 하는 경우, 리포지토리 패턴이 제한적일 수 있습니다.