
순위 검색
https://school.programmers.co.kr/learn/courses/30/lessons/72412
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
카카오는 하반기 경력 개발자 공개채용을 진행 중에 있으며 현재 지원서 접수와 코딩테스트가 종료되었습니다.
이번 채용에서 지원자는 지원서 작성 시 아래와 같이 4가지 항목을 반드시 선택하도록 하였습니다.
코딩테스트 참여 개발언어 항목에 cpp, java, python 중 하나를 선택해야 합니다.
지원 직군 항목에 backend와 frontend 중 하나를 선택해야 합니다.
지원 경력구분 항목에 junior와 senior 중 하나를 선택해야 합니다.
선호하는 소울푸드로 chicken과 pizza 중 하나를 선택해야 합니다.
인재영입팀에 근무하고 있는 니니즈는 코딩테스트 결과를 분석하여 채용에 참여한 개발팀들에 제공하기 위해
지원자들의 지원 조건을 선택하면 해당 조건에 맞는 지원자가 몇 명인 지 쉽게 알 수 있는 도구를 만들고 있습니다.
예를 들어, 개발팀에서 궁금해하는 문의사항은 다음과 같은 형태가 될 수 있습니다.
코딩테스트에 java로 참여했으며, backend 직군을 선택했고, junior 경력이면서,
소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 50점 이상 받은 지원자는 몇 명인가?
물론 이 외에도 각 개발팀의 상황에 따라 아래와 같이 다양한 형태의 문의가 있을 수 있습니다.
코딩테스트에 python으로 참여했으며, frontend 직군을 선택했고, senior 경력이면서, 소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
코딩테스트에 cpp로 참여했으며, senior 경력이면서, 소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
backend 직군을 선택했고, senior 경력이면서 코딩테스트 점수를 200점 이상 받은 사람은 모두 몇 명인가?
소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 250점 이상 받은 사람은 모두 몇 명인가?
코딩테스트 점수를 150점 이상 받은 사람은 모두 몇 명인가?
즉, 개발팀에서 궁금해하는 내용은 다음과 같은 형태를 갖습니다.
[조건]을 만족하는 사람 중 코딩테스트 점수를 X점 이상 받은 사람은 모두 몇 명인가?
[문제]
지원자가 지원서에 입력한 4가지의 정보와 획득한 코딩테스트 점수를 하나의 문자열로 구성한 값의 배열 info,
개발팀이 궁금해하는 문의조건이 문자열 형태로 담긴 배열 query가 매개변수로 주어질 때,
각 문의조건에 해당하는 사람들의 숫자를 순서대로 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
[제한사항]
- info 배열의 크기는 1 이상 50,000 이하입니다.
- info 배열 각 원소의 값은 지원자가 지원서에 입력한 4가지 값과 코딩테스트 점수를 합친 “개발언어 직군 경력 소울푸드 점수” 형식입니다.
- 개발언어는 cpp, java, python 중 하나입니다.
- 직군은 backend, frontend 중 하나입니다.
- 경력은 junior, senior 중 하나입니다.
- 소울푸드는 chicken, pizza 중 하나입니다.
- 점수는 코딩테스트 점수를 의미하며, 1 이상 100,000 이하인 자연수입니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- query 배열의 크기는 1 이상 100,000 이하입니다.
- query의 각 문자열은 “[조건] X” 형식입니다.
- [조건]은 “개발언어 and 직군 and 경력 and 소울푸드” 형식의 문자열입니다.
- 언어는 cpp, java, python, – 중 하나입니다.
- 직군은 backend, frontend, – 중 하나입니다.
- 경력은 junior, senior, – 중 하나입니다.
- 소울푸드는 chicken, pizza, – 중 하나입니다.
- ‘-‘ 표시는 해당 조건을 고려하지 않겠다는 의미입니다.
- X는 코딩테스트 점수를 의미하며 조건을 만족하는 사람 중 X점 이상 받은 사람은 모두 몇 명인 지를 의미합니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- 예를 들면, “cpp and – and senior and pizza 500″은 “cpp로 코딩테스트를 봤으며,
경력은 senior 이면서 소울푸드로 pizza를 선택한 지원자 중 코딩테스트 점수를 500점 이상 받은 사람은 모두 몇 명인가?”를 의미합니다.
[입출력 예]
| info | query | result |
|---|---|---|
["java backend junior pizza 150","python frontend senior chicken 210","python frontend senior chicken 150","cpp backend senior pizza 260","java backend junior chicken 80","python backend senior chicken 50"] | ["java and backend and junior and pizza 100","python and frontend and senior and chicken 200","cpp and - and senior and pizza 250","- and backend and senior and - 150","- and - and - and chicken 100","- and - and - and - 150"] | [1,1,1,1,2,4] |
입출력 예에 대한 설명
지원자 정보를 표로 나타내면 다음과 같습니다.
| 언어 | 직군 | 경력 | 소울 푸드 | 점수 |
|---|---|---|---|---|
| java | backend | junior | pizza | 150 |
| python | frontend | senior | chicken | 210 |
| python | frontend | senior | chicken | 150 |
| cpp | backend | senior | pizza | 260 |
| java | backend | junior | chicken | 80 |
| python | backend | senior | chicken | 50 |
"java and backend and junior and pizza 100": java로 코딩테스트를 봤으며,
backend 직군을 선택했고 junior 경력이면서 소울푸드로 pizza를 선택한 지원자 중
코딩테스트 점수를 100점 이상 받은 지원자는 1명 입니다."python and frontend and senior and chicken 200": python으로 코딩테스트를 봤으며,
frontend 직군을 선택했고, senior 경력이면서 소울 푸드로 chicken을 선택한 지원자 중
코딩테스트 점수를 200점 이상 받은 지원자는 1명 입니다."cpp and - and senior and pizza 250": cpp로 코딩테스트를 봤으며,
senior 경력이면서 소울푸드로 pizza를 선택한 지원자 중
코딩테스트 점수를 250점 이상 받은 지원자는 1명 입니다."- and backend and senior and - 150": backend 직군을 선택했고,
senior 경력인 지원자 중 코딩테스트 점수를 150점 이상 받은 지원자는 1명 입니다."- and - and - and chicken 100": 소울푸드로 chicken을 선택한 지원자 중
코딩테스트 점수를 100점 이상을 받은 지원자는 2명 입니다."- and - and - and - 150": 코딩테스트 점수를 150점 이상 받은 지원자는 4명 입니다.
효율성 실패 코드
#include <string>
#include <vector>
#include <iostream>
#include <cstdlib>
#include <sstream>
#include <tuple>
using namespace std;
vector<tuple<int, int, int, int, int>> myVector;
vector<int> solution(vector<string> info, vector<string> query) {
vector<int> answer;
int _Index = 1;
for (auto& it : info) {
istringstream ss(it);
vector<string> words; // 자른 문자열을 저장할 벡터
string _Temp; // 임시
// 스트림을 한 줄씩 읽어, 공백 단위로 분리한 뒤, 결과를 벡터에 저장
while (getline(ss, _Temp, ' ')) words.push_back(_Temp);
int _Lang, _Career, _Group, _Food, _Score;
if (words[0] == "cpp") _Lang = 0; // 언어
else if(words[0] == "java") _Lang = 1;
else _Lang = 2;
if (words[1] == "backend") _Group = 0; // 직군
else _Group = 1;
if (words[2] == "senior") _Career = 0; // 경력
else _Career = 1;
if (words[3] == "chicken") _Food = 0; // 소울푸드
else _Food = 1;
_Score = atoi(words[4].c_str()); // 점수
myVector.push_back({make_tuple(_Lang, _Group, _Career, _Food, _Score) });
}
for (auto& it : query) {
istringstream ss(it);
vector<string> words; // 자른 문자열을 저장할 벡터
string _Temp; // 임시
// 스트림을 한 줄씩 읽어, 공백 단위로 분리한 뒤, 결과를 벡터에 저장
while (getline(ss, _Temp, ' ')) {
if (_Temp == "and") continue;
words.push_back(_Temp);
}
int _Lang = -1, _Career = -1, _Group = -1, _Food = -1, _Score = 0, _Res = 0;
if (words[0] == "cpp") _Lang = 0; // 언어
else if (words[0] == "java") _Lang = 1;
else if (words[0] == "python") _Lang = 2;
if (words[1] == "backend") _Group = 0; // 직군
else if (words[1] == "frontend") _Group = 1;
if (words[2] == "senior") _Career = 0; // 경력
else if (words[2] == "junior") _Career = 1;
if (words[3] == "chicken") _Food = 0; // 소울푸드
else if (words[3] == "pizza") _Food = 1;
if (words[4] != "-") _Score = atoi(words[4].c_str()); // 점수
for (auto& it : myVector) {
if (get<0>(it) != _Lang && _Lang != -1) continue;
if (get<1>(it) != _Group && _Group != -1) continue;
if (get<2>(it) != _Career && _Career != -1) continue;
if (get<3>(it) != _Food && _Food != -1) continue;
if (get<4>(it) < _Score) continue;
_Res++;
}
answer.push_back(_Res);
}
return answer;
}
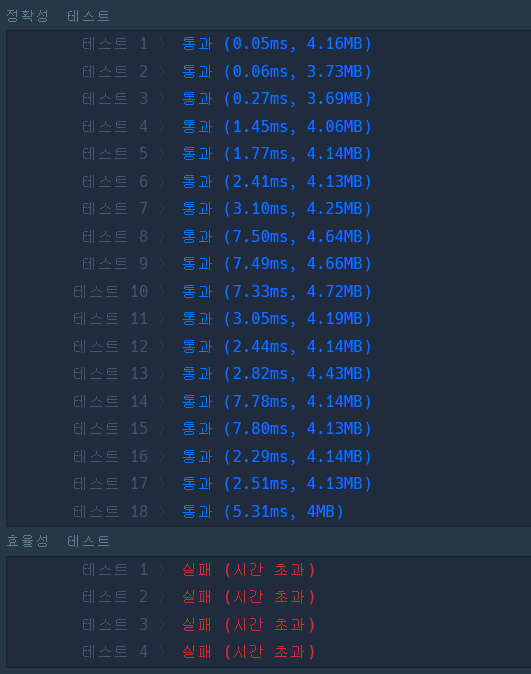
효율성 테스트를 통과하기 위해서는 쿼리를 받자마자 결과가 나와야함
(위의 코드는 쿼리가 들어오면 모든 정보를 순회하면서 찾는 방식)
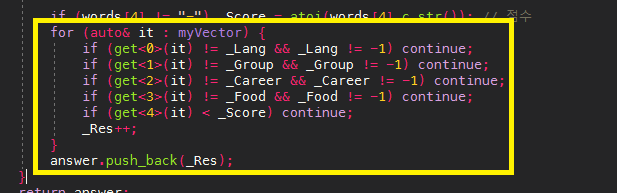
통과된 코드
#include <string>
#include <vector>
#include <iostream>
#include <cstdlib>
#include <sstream>
#include <algorithm>
using namespace std;
vector<int> myVector[4][3][3][3];
vector<int> solution(vector<string> info, vector<string> query) {
vector<int> answer;
for (auto& it : info) {
istringstream ss(it);
vector<string> words; // 자른 문자열을 저장할 벡터
string _Temp; // 임시
// 스트림을 한 줄씩 읽어, 공백 단위로 분리한 뒤, 결과를 벡터에 저장
while (getline(ss, _Temp, ' ')) words.push_back(_Temp);
int _Lang, _Career, _Group, _Food, _Score;
if (words[0] == "cpp") _Lang = 1; // 언어
else if(words[0] == "java") _Lang = 2;
else _Lang = 3;
if (words[1] == "backend") _Group = 1; // 직군
else _Group = 2;
if (words[2] == "senior") _Career = 1; // 경력
else _Career = 2;
if (words[3] == "chicken") _Food = 1; // 소울푸드
else _Food = 2;
_Score = atoi(words[4].c_str()); // 점수
myVector[0][0][0][0].push_back(_Score);
myVector[_Lang][0][0][0].push_back(_Score);
myVector[_Lang][_Group][0][0].push_back(_Score);
myVector[_Lang][_Group][_Career][0].push_back(_Score);
myVector[_Lang][_Group][_Career][_Food].push_back(_Score);
myVector[_Lang][_Group][0][_Food].push_back(_Score);
myVector[_Lang][0][_Career][0].push_back(_Score);
myVector[_Lang][0][_Career][_Food].push_back(_Score);
myVector[_Lang][0][0][_Food].push_back(_Score);
myVector[0][_Group][0][0].push_back(_Score);
myVector[0][_Group][_Career][0].push_back(_Score);
myVector[0][_Group][_Career][_Food].push_back(_Score);
myVector[0][_Group][0][_Food].push_back(_Score);
myVector[0][0][_Career][0].push_back(_Score);
myVector[0][0][_Career][_Food].push_back(_Score);
myVector[0][0][0][_Food].push_back(_Score);
}
// 빠른 쿼리 검색을 위해서 정렬
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 3; j++){
for (int k = 0; k < 3; k++){
for (int l = 0; l < 3; l++) {
sort(myVector[i][j][k][l].begin(), myVector[i][j][k][l].end());
}
}
}
}
for (auto& it : query) {
istringstream ss(it);
vector<string> words; // 자른 문자열을 저장할 벡터
string _Temp; // 임시
// 스트림을 한 줄씩 읽어, 공백 단위로 분리한 뒤, 결과를 벡터에 저장
while (getline(ss, _Temp, ' ')) {
if (_Temp == "and") continue;
words.push_back(_Temp);
}
int _Lang = 0, _Career = 0, _Group = 0, _Food = 0, _Score = 0;
if (words[0] == "cpp") _Lang = 1; // 언어
else if (words[0] == "java") _Lang = 2;
else if (words[0] == "python") _Lang = 3;
if (words[1] == "backend") _Group = 1; // 직군
else if (words[1] == "frontend") _Group = 2;
if (words[2] == "senior") _Career = 1; // 경력
else if (words[2] == "junior") _Career = 2;
if (words[3] == "chicken") _Food = 1; // 소울푸드
else if (words[3] == "pizza") _Food = 2;
if (words[4] != "-") _Score = atoi(words[4].c_str()); // 점수
// _Score 이상의 수가 나오는 it 반환
auto iter = lower_bound(myVector[_Lang][_Group][_Career][_Food].begin(), myVector[_Lang][_Group][_Career][_Food].end(), _Score);
if (iter == myVector[_Lang][_Group][_Career][_Food].end()) answer.push_back(0); // end() 반환은 값이 없다는 이야기
else answer.push_back(myVector[_Lang][_Group][_Career][_Food].size() - (iter - myVector[_Lang][_Group][_Career][_Food].begin()));
}
return answer;
}
나올 수 있는 모든 쿼리
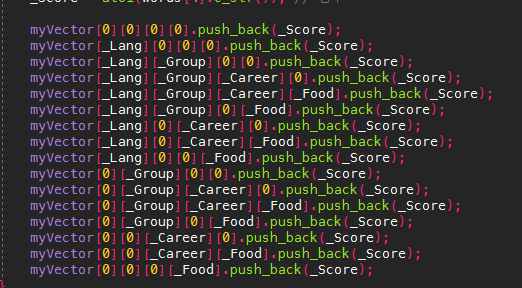
lower_bound를 이용한 확인

lower_bound는 이진 탐색을 이용하여 정렬된 벡터에서 해당 값(_Score)이 처음으로 나타나는 위치를 찾아 그 위치를 반환
만약 lower_bound가 반환한 위치가 myVector[_Lang][_Group][_Career][_Food]의 end()를 가리킨다면,
해당 값이 벡터에 없는 것이므로 answer 벡터에 0을 push_back합니다.
만약 lower_bound가 반환한 위치가 myVector[_Lang][_Group][_Career][_Food]의 end()를 가리키지 않는다면,
해당 값이 벡터에서 처음 나타나는 위치를 가리킨다.
이 iterator에서 벡터의 시작 iterator를 빼면, 해당 값이 위치하는 인덱스를 알 수 있습니다.
이때, 벡터의 사이즈에서 해당 인덱스를 뺀 값이, 해당 값보다 큰 값들의 개수가 됩니다.

![백준 2609번 (최대공약수와 최소공배수, C++) [BAEKJOON]](https://lycos7560.com/wp-content/uploads/boj-og-1.png)
![백준 9465번 (스티커, C++) [BAEKJOON]](https://lycos7560.com/wp-content/uploads/boj-og.png)
![백준 2606번 (바이러스, C++, BFS) [BAEKJOON]](https://lycos7560.com/wp-content/uploads/2022/10/boj-og-1-2048x1070-1-1024x535.png)
![Programmers 17683 [3차] 방금그곡 [2018 KAKAO BLIND RECRUITMENT]](https://lycos7560.com/wp-content/uploads/2023/03/programmers.jpg)